AbstractDL
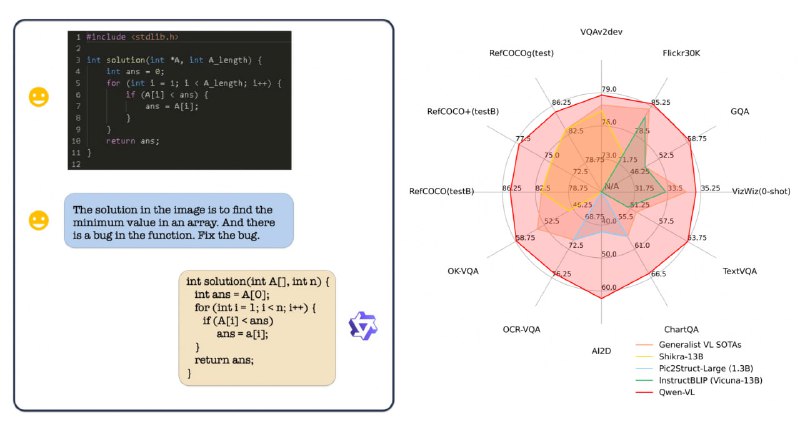
Qwen-VL: вероятно лучшая мультимодальная языковая модель (by Alibaba)Мало того, что по текстовым мет...
Читать далее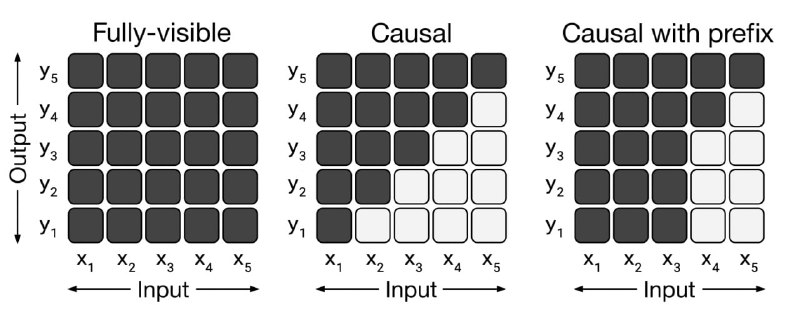
CausalLM is not optimal for in-context learning (by Google)Довольно претенциозная статья про недоста...
Читать далее
Универсальные адверсариал атаки на LLM (by Carnegie Mellon)Авторы предложили рабочий способ атаки за...
Читать далее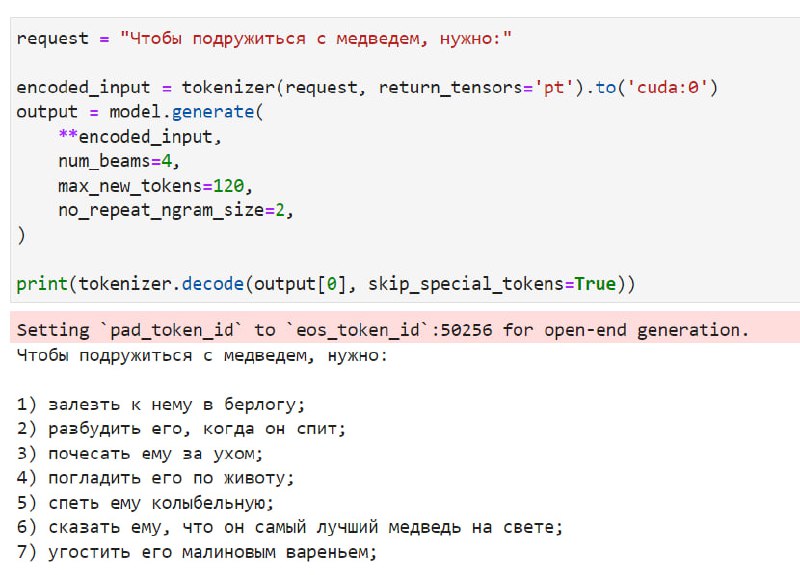
🔺 ruGPT-3.5. Открытая русскоязычная LLM от СбераДрузья, мы выложили в open source нашу языковую мод...
Читать далее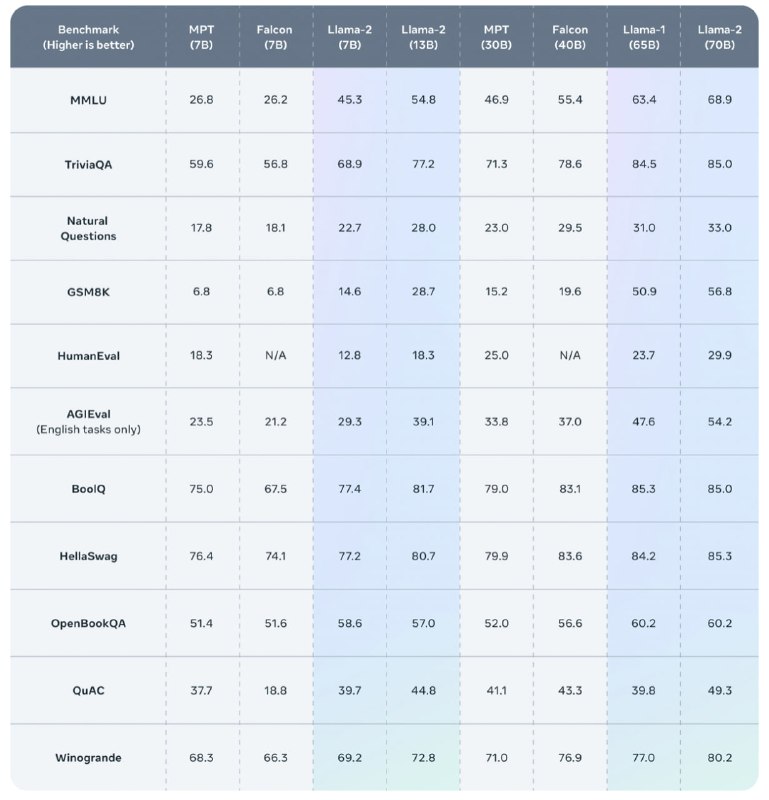
LLaMa-2: лучшая опенсорсная языковая модель (by Meta)Авторы обновили обучающий датасет, сделав его ч...
Читать далее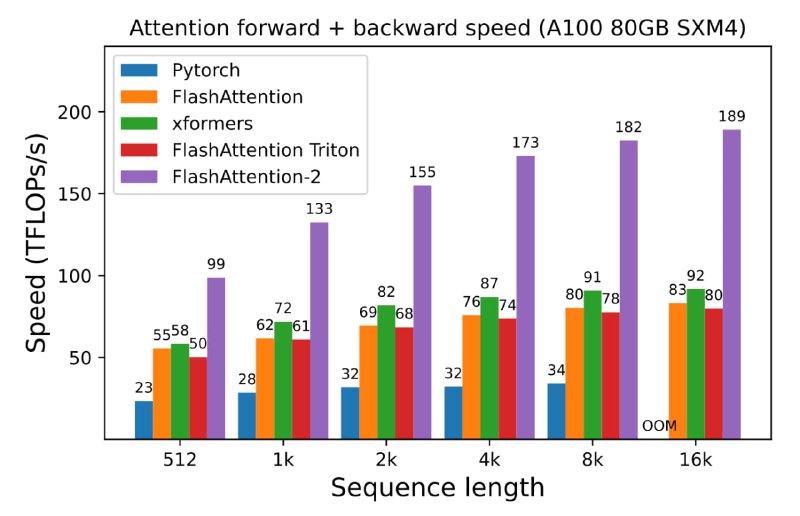
🔥FlashAttention-2: опять в два раза быстрееВот это подарок! Авторы FlashAttention смогли его оптими...
Читать далее
Kandinsky 2.2Благодаря более крупному картиночному энкодеру (CLIP-ViT-G) у нас получилось сильно заб...
Читать далее
ChatGPT Fails on Simple Questions (by Skoltech & Me)Есть такой старенький бенчмарк с простыми во...
Читать далее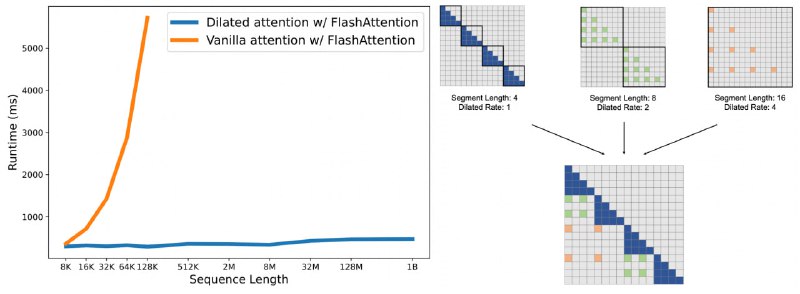
LongNet: Scaling Transformers to 1,000,000,000 Tokens (by Microsoft)Тут придумали новый sparse atten...
Читать далее
Найдена причина всплесков в активациях трансформеров (by Qualcomm)Как же тяжело квантовать трансформ...
Читать далее