CausalLM is not optimal for in-context learning (by Google)
Довольно претенциозная статья про недостатки causal attention и, следовательно, превосходство PaLM над GPT.
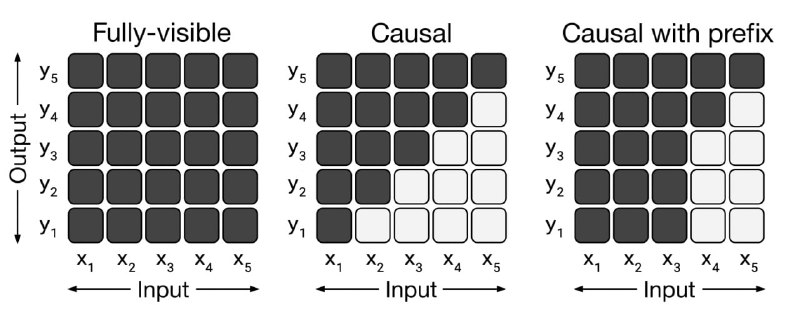
Авторам удалось экспериментально и теоретически показать, что префиксные языковые модели (T5, PaLM, UL-2) лучше понимают few-shot демонстрации и даже могут находить оптимальное (по MSE) решение задач регрессии, в отличие от каузальных языковых моделей (GPT, LLaMa). Похоже, что треугольное маскирование внимания (causal attention) сильно ограничивает сложность операций с внутренними представлениями.
Статья
Довольно претенциозная статья про недостатки causal attention и, следовательно, превосходство PaLM над GPT.
Авторам удалось экспериментально и теоретически показать, что префиксные языковые модели (T5, PaLM, UL-2) лучше понимают few-shot демонстрации и даже могут находить оптимальное (по MSE) решение задач регрессии, в отличие от каузальных языковых моделей (GPT, LLaMa). Похоже, что треугольное маскирование внимания (causal attention) сильно ограничивает сложность операций с внутренними представлениями.
Статья