Я, наконец, опубликовал statoscope 5.25 🎉
И знаете, что? Я очень рад. Хотя бы потому, что теперь statoscope-отчет со сравнением двух (master vs PR) клиентских сборок Яндекс Маркета весит не 494мб, а 11мб.
Нет, вам не кажется - статы пожались почти в 45 раз эффективнее 😇
Получаем экономия квоты на железо и время пользователя, который ждет пока отчет загрузится.
Это стало возможным благодаря сжатию статов в Binary JSON.
Если очень коротко, то значения из объекта компактно записываются в виде байтов, поверх применяются всякие оптимизации типа дедупликации значений и компактного представления строк и массивов. В результате получается сплошной поток типов и данных. Никаких скобочек, кавычек и форматирования, а данные записаны компактно. Это все будет иметь заметный эффект на большом объеме данных (например, от 10мб).
Возможно, вы задаетесь вопросом: "А почему нельзя обойтись просто gzip'ом?". Binary JSON + gzip жмет в 2 раза лучше, чем просто gzip. А все потому, что сжимая JSON gzip'ом - мы сжимаем "что-то там чем-то там", а сжимая JSON инструментом, который заточен под JSON (знаем формат и специфику данных) - мы сжимаем именно JSON и делаем это эффективно. Да, многое зависит от структуры исходных данных, но я смотрю на реальные данные в виде статов Яндекс Маркета и вижу огромный профит.
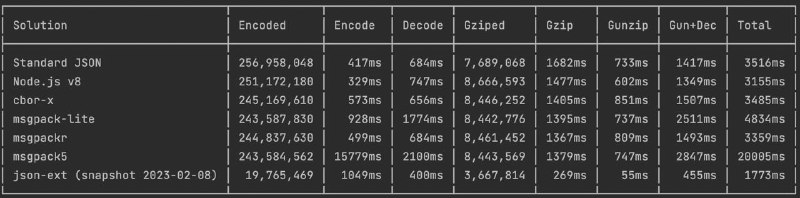
На скриншоте можно посмотреть сравнение json-ext с другими решениями, которые умеют в binary JSON. Сравнение проводится на примере нормализованных статов клиентской сборки Яндекс Маркета. Как видите, идея binary JSON не нова и эксперименты в этой области продолжаются, но судя по всему, остальные остановились на достигнутом и json-ext пока впереди 🤓
Думаю @gorshochekvarit еще сам расскажет подробнее про это. Хотя я и сам приложил руку с энкодеру/декодеру, но после этого Роман накоммитил туда много всяких интересных оптимизаций (например, хранение массивов как колоночную БД, что позволяет компактнее их хранить).
И знаете, что? Я очень рад. Хотя бы потому, что теперь statoscope-отчет со сравнением двух (master vs PR) клиентских сборок Яндекс Маркета весит не 494мб, а 11мб.
Нет, вам не кажется - статы пожались почти в 45 раз эффективнее 😇
Получаем экономия квоты на железо и время пользователя, который ждет пока отчет загрузится.
Это стало возможным благодаря сжатию статов в Binary JSON.
Если очень коротко, то значения из объекта компактно записываются в виде байтов, поверх применяются всякие оптимизации типа дедупликации значений и компактного представления строк и массивов. В результате получается сплошной поток типов и данных. Никаких скобочек, кавычек и форматирования, а данные записаны компактно. Это все будет иметь заметный эффект на большом объеме данных (например, от 10мб).
Возможно, вы задаетесь вопросом: "А почему нельзя обойтись просто gzip'ом?". Binary JSON + gzip жмет в 2 раза лучше, чем просто gzip. А все потому, что сжимая JSON gzip'ом - мы сжимаем "что-то там чем-то там", а сжимая JSON инструментом, который заточен под JSON (знаем формат и специфику данных) - мы сжимаем именно JSON и делаем это эффективно. Да, многое зависит от структуры исходных данных, но я смотрю на реальные данные в виде статов Яндекс Маркета и вижу огромный профит.
На скриншоте можно посмотреть сравнение json-ext с другими решениями, которые умеют в binary JSON. Сравнение проводится на примере нормализованных статов клиентской сборки Яндекс Маркета. Как видите, идея binary JSON не нова и эксперименты в этой области продолжаются, но судя по всему, остальные остановились на достигнутом и json-ext пока впереди 🤓
Думаю @gorshochekvarit еще сам расскажет подробнее про это. Хотя я и сам приложил руку с энкодеру/декодеру, но после этого Роман накоммитил туда много всяких интересных оптимизаций (например, хранение массивов как колоночную БД, что позволяет компактнее их хранить).