На подходе новая сетка на 1.2 триллиона параметров
https://www.together.xyz/blog/redpajama
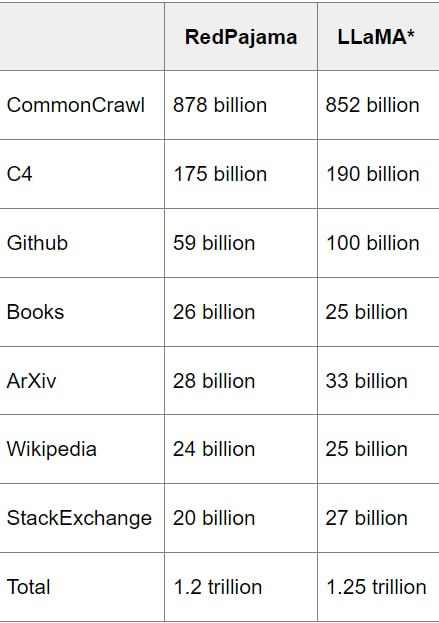
Полный набор данных RedPajama на 1,2 триллиона токенов и меньшую, но более удобную случайную выборку можно загрузить через Hugging Face. Полный набор данных составляет ~5 ТБ в разархивированном виде на диске и ~3 ТБ в сжатом виде для скачивания.
RedPajama-Data-1T состоит из семи срезов данных:
CommonCrawl: пять дампов CommonCrawl, обработанных с использованием конвейера CCNet и отфильтрованных с помощью нескольких фильтров качества, включая линейный классификатор, который выбирает страницы, подобные Википедии.
C4: стандартный набор данных C4
GitHub: данные GitHub, отфильтрованные по лицензиям и качеству.
arXiv: удаление шаблонов из научных статей
Книги: корпус открытых книг, дедуплицированный по сходству содержания.
Википедия: подмножество страниц Википедии, удаление шаблонного кода.
StackExchange: Подмножество популярных веб-сайтов в StackExchange, удаление шаблонного кода.
https://www.together.xyz/blog/redpajama
Полный набор данных RedPajama на 1,2 триллиона токенов и меньшую, но более удобную случайную выборку можно загрузить через Hugging Face. Полный набор данных составляет ~5 ТБ в разархивированном виде на диске и ~3 ТБ в сжатом виде для скачивания.
RedPajama-Data-1T состоит из семи срезов данных:
CommonCrawl: пять дампов CommonCrawl, обработанных с использованием конвейера CCNet и отфильтрованных с помощью нескольких фильтров качества, включая линейный классификатор, который выбирает страницы, подобные Википедии.
C4: стандартный набор данных C4
GitHub: данные GitHub, отфильтрованные по лицензиям и качеству.
arXiv: удаление шаблонов из научных статей
Книги: корпус открытых книг, дедуплицированный по сходству содержания.
Википедия: подмножество страниц Википедии, удаление шаблонного кода.
StackExchange: Подмножество популярных веб-сайтов в StackExchange, удаление шаблонного кода.