Вы наверняка уже прочитали этот пейпер, ведь он вышел в доисторические времена по меркам ИИ. А именно, позавчера.
GPT-4 дали несколько тысяч новых задач из университетского курса MIT по математике, программированию, электромеханике, ни одна из которых гарантированно не участвовала в данных для тренировки модели.
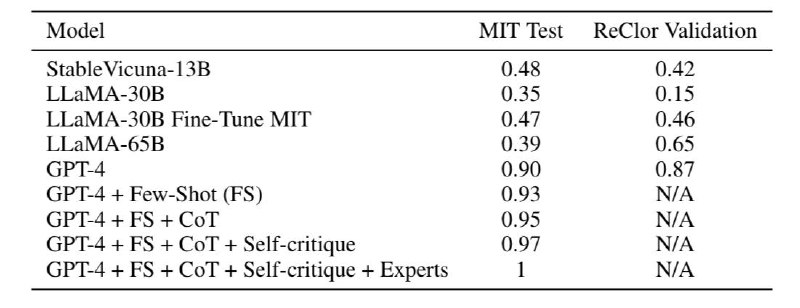
GPT-4 из коробки справился на 90% без каких-либо дополнительных действий, НО
Самое интересное, что использование всех описанных в этом канале ранее методов промтинга дали результат в 100% верно решенных задач. В таблице приведена разница в качестве в зависимости от механик промптинга. Вот краткое их описание:
1. Few-shot: промт с примерами решения других задач
2. CoT: просьба модель озвучить свою цепочку рассуждений и мыслей
3. ToS: я описал тут
4. Программирование: вместо решения задачи, LLM пишет код, который детерминированно решает эту и подобные задачи
5. Критик: модель критикует сама себя
6. Эксперт: модель «косплеит» эксперта («представь что ты профессор ЭмАйТи по математике…»)
Вывод: это не модель тупая, а промптер криворукий
GPT-4 дали несколько тысяч новых задач из университетского курса MIT по математике, программированию, электромеханике, ни одна из которых гарантированно не участвовала в данных для тренировки модели.
GPT-4 из коробки справился на 90% без каких-либо дополнительных действий, НО
Самое интересное, что использование всех описанных в этом канале ранее методов промтинга дали результат в 100% верно решенных задач. В таблице приведена разница в качестве в зависимости от механик промптинга. Вот краткое их описание:
1. Few-shot: промт с примерами решения других задач
2. CoT: просьба модель озвучить свою цепочку рассуждений и мыслей
3. ToS: я описал тут
4. Программирование: вместо решения задачи, LLM пишет код, который детерминированно решает эту и подобные задачи
5. Критик: модель критикует сама себя
6. Эксперт: модель «косплеит» эксперта («представь что ты профессор ЭмАйТи по математике…»)
Вывод: это не модель тупая, а промптер криворукий