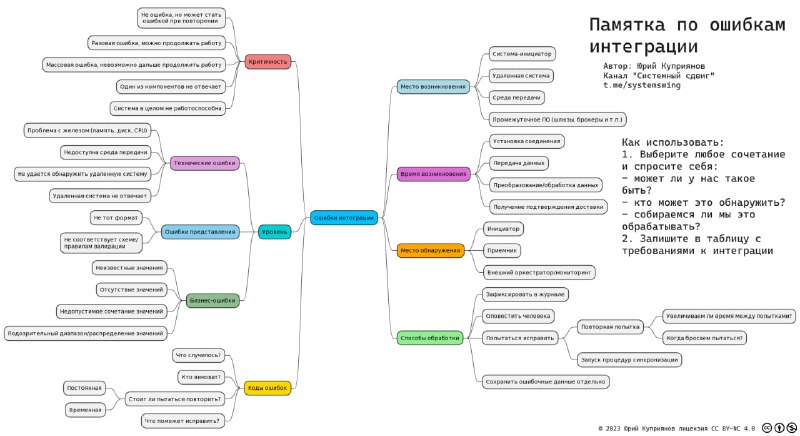
Сделал для вас памятку по ошибкам интеграции: на какие вопросы стоит ответить, чтобы охватить все возможные варианты ошибок.
Все ошибки делятся:
➡️ по месту возникновения:
- проблемы с клиентом (системой, которая запрашивает или передаёт данные)
- проблемы с сервером (система, которая отвечает на запрос)
- проблемы со средой передачи (сетью)
- проблемы с промежуточными системами (шлюзами, брокерами, преобразователями и т.п.)
➡️ по времени возникновения:
- при обращении к серверу
- при передаче/преобразовании данных (особенно если у нас длинный или составной запрос)
- при получении подтверждения успешного получения от сервера
➡️ по критичности:
- ещё не ошибка, но при частом повторении станет ошибкой (например, система слишком долго отвечает)
- разовая ошибка, можно продолжать работу
- массовая ошибка, невозможно дальше продолжить работу
- один из компонентов не отвечает, но система в целом работоспособна и может это выявить
- система в целом не работоспособна, выявить может только внешний мониторинг
➡️ по уровню:
- технические ошибки (нет связи, таймаут)
- ошибки представления: не тот протокол или формат данных (ждали xml, пришел json)
- логические или бизнес ошибки (со связью всё в порядке, но сами данные не такие, как требуется: чего-то не хватает или лишнее, но без понимания смысла данных распознать ошибку невозможно)
Смотрим на возможные сочетания, принимаем решение:
— в нашей системе такое может быть?
— кто это может обнаружить?
— как системы информируют друг друга, какие есть соглашения о кодах ошибок?
— как мы это будем обрабатывать?
Заносим каждую ситуацию в таблицу с конкретными данными. Можно таблицу разбить на несколько: по уровням ошибок (технические/бизнесовые) или по компонентам, которые могут ошибки обнаружить / попробовать исправить.
Пользуйтесь!
Все ошибки делятся:
➡️ по месту возникновения:
- проблемы с клиентом (системой, которая запрашивает или передаёт данные)
- проблемы с сервером (система, которая отвечает на запрос)
- проблемы со средой передачи (сетью)
- проблемы с промежуточными системами (шлюзами, брокерами, преобразователями и т.п.)
➡️ по времени возникновения:
- при обращении к серверу
- при передаче/преобразовании данных (особенно если у нас длинный или составной запрос)
- при получении подтверждения успешного получения от сервера
➡️ по критичности:
- ещё не ошибка, но при частом повторении станет ошибкой (например, система слишком долго отвечает)
- разовая ошибка, можно продолжать работу
- массовая ошибка, невозможно дальше продолжить работу
- один из компонентов не отвечает, но система в целом работоспособна и может это выявить
- система в целом не работоспособна, выявить может только внешний мониторинг
➡️ по уровню:
- технические ошибки (нет связи, таймаут)
- ошибки представления: не тот протокол или формат данных (ждали xml, пришел json)
- логические или бизнес ошибки (со связью всё в порядке, но сами данные не такие, как требуется: чего-то не хватает или лишнее, но без понимания смысла данных распознать ошибку невозможно)
Смотрим на возможные сочетания, принимаем решение:
— в нашей системе такое может быть?
— кто это может обнаружить?
— как системы информируют друг друга, какие есть соглашения о кодах ошибок?
— как мы это будем обрабатывать?
Заносим каждую ситуацию в таблицу с конкретными данными. Можно таблицу разбить на несколько: по уровням ошибок (технические/бизнесовые) или по компонентам, которые могут ошибки обнаружить / попробовать исправить.
Пользуйтесь!