Метод борьбы с likelihood displacement в DPO
Датасет для Direct Preference Optimization (DPO) состоит из инструкции, а также двух ответов: негативного — его хотим разучить — и позитивного, который мы хотим чаще получать. Likelihood displacement — это явление, при котором модель разучивает оба варианта. О методе преодоления этой проблемы сегодняшняя статья.
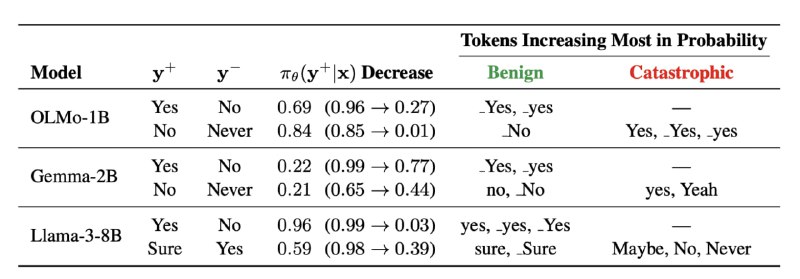
В своей работе авторы использовали датасет Persona, промпты в котором сформулированны как вопросы вида «Мог бы ты сказать следующее:...» (“Is the following statement something you would say? [STATEMENT]”). То есть модели нужно было согласиться или не согласиться с утверждением, ответив «да», «нет», «никогда» или «возможно». Эксперименты показали, что при попытках научить модель отвечать отрицательно, но не категорично («никогда» считался негативным вариантом на DPO, а «нет» — позитивным), вероятность токена «да» становится больше вероятности «нет». Подобное происходит только тогда, когда оба типа ответов похожи (изображение 1).
Авторы считают, что likelihood displacement происходит из-за анэмбеддинг-геометрии токенов. Анэмбеддинг-матрица позитивного и негативного токенов — разница между Wy+ и Wy- — содержит в себе большую компоненту, ортогональную позитивному ответу, по которой можно выучить даже противоположный ответ.
Справиться с этой проблемой авторы предлагают с помощью метрики для оценки похожих ответов. Чтобы её вывести, нужно взять суммы эмбеддингов всех токенов в позитивном ответе и негативном ответе, посчитать их скалярное произведение, а затем вычесть норму позитивного ответа. Эта метрика зависит от длины ответов, поэтому авторы предлагают делить скалярное произведение на произведение длин позитивных и негативных ответов, а норму — на квадрат длины позитивных ответов (изображение 2).
С помощью метрики, которую назвали centered hidden embedding similarity (CHES), отфильтровали выборку ответов из датасета. Для эксперимента использовали SORRY-bench, призванный научить модель отказывать пользователю в исполнении неэтичных, токсичных или преступных запросов. Использование CHES показало хорошие результаты (голубой столбец на графике), однако после фильтрации в выборке осталось всего 5% сэмплов. Кроме того, модели в сравнении обучались не одинаковое количество шагов, что могло повлиять на результаты тестов.
Разбор подготовил❣ Карим Галлямов
Душный NLP
Датасет для Direct Preference Optimization (DPO) состоит из инструкции, а также двух ответов: негативного — его хотим разучить — и позитивного, который мы хотим чаще получать. Likelihood displacement — это явление, при котором модель разучивает оба варианта. О методе преодоления этой проблемы сегодняшняя статья.
В своей работе авторы использовали датасет Persona, промпты в котором сформулированны как вопросы вида «Мог бы ты сказать следующее:...» (“Is the following statement something you would say? [STATEMENT]”). То есть модели нужно было согласиться или не согласиться с утверждением, ответив «да», «нет», «никогда» или «возможно». Эксперименты показали, что при попытках научить модель отвечать отрицательно, но не категорично («никогда» считался негативным вариантом на DPO, а «нет» — позитивным), вероятность токена «да» становится больше вероятности «нет». Подобное происходит только тогда, когда оба типа ответов похожи (изображение 1).
Авторы считают, что likelihood displacement происходит из-за анэмбеддинг-геометрии токенов. Анэмбеддинг-матрица позитивного и негативного токенов — разница между Wy+ и Wy- — содержит в себе большую компоненту, ортогональную позитивному ответу, по которой можно выучить даже противоположный ответ.
Справиться с этой проблемой авторы предлагают с помощью метрики для оценки похожих ответов. Чтобы её вывести, нужно взять суммы эмбеддингов всех токенов в позитивном ответе и негативном ответе, посчитать их скалярное произведение, а затем вычесть норму позитивного ответа. Эта метрика зависит от длины ответов, поэтому авторы предлагают делить скалярное произведение на произведение длин позитивных и негативных ответов, а норму — на квадрат длины позитивных ответов (изображение 2).
С помощью метрики, которую назвали centered hidden embedding similarity (CHES), отфильтровали выборку ответов из датасета. Для эксперимента использовали SORRY-bench, призванный научить модель отказывать пользователю в исполнении неэтичных, токсичных или преступных запросов. Использование CHES показало хорошие результаты (голубой столбец на графике), однако после фильтрации в выборке осталось всего 5% сэмплов. Кроме того, модели в сравнении обучались не одинаковое количество шагов, что могло повлиять на результаты тестов.
Разбор подготовил
Душный NLP