Механизм аттеншена NSA
Native Sparse Attention (NSA) — механизм разреженного аттеншена от инженеров из DeepSeek. Утверждается, что NSA имеет качество, сопоставимое с обычным аттеншном на маленьких контекстах, и значительно опережает его на больших — в статье сравнение производится на 64K токенов.
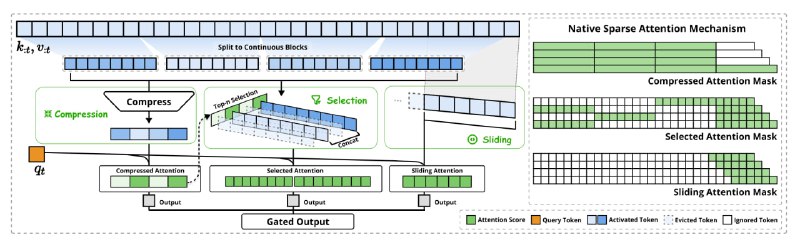
Вместо того чтобы каждый новый query обращался ко всем предыдущим key и value, как это делается в традиционном аттеншне, авторы предлагают сжимать предыдущие ключи и значения в dense-представления. За счёт этого длина последовательности, над которой работает attention, уменьшается, что позволяет работать с контекстом в 64K токенов так, будто их всего 4K. В отличие от предыдущих sparse-методов аттеншна (например, Quest), NSA применяется как при обучении, так и при инференсе.
В статье предлагают три функции для сжатия представления: token compression, token selection и sliding window. Для каждой из них считается аттеншен, а результаты складываются с коэффициентами от MLP-блока.
Token compression предполагает покрытие последовательностей ключей и значений блоками длины 32 с перекрытием по 16 токенов с последующим сжатием каждого блока в «один токен» с помощью MLP с внутриблочным позиционным энкодингом.
На стадии token selection тоже происходит покрытие ключей и значений блоками, но теперь для каждого из них считается скор полезности. После чего выбираются top-16 блоков с максимальным скором. На оставшиеся блоки аттеншн не смотрит, а в выбранных внимание обращается на все ключи и значения.
Авторы отмечают, что в начале обучения сильно доминировали локальные паттерны. Поэтому selection и compression больше фокусировались на последовательностях ближе к текущему токену. В конце, на длинных контекстах, возникали сложности с аттеншеном на начало последовательности. Чтобы решить эту проблему, предлагается дополнительно использовать sliding window для аттеншена на ближайшие 512 токенов.
Метод проверяли на MoE-модели на 27B параметров, из которых 3B — активные. У модели было 30 слоёв аттеншена и 64 головы с разной размерностью. Число экспертов — 72, из них общих — 2. Обучение происходило на 270B токенов с размером контекстного окна в 8K токенов. Далее был SFT с использованием техники YaRN.
Результаты тестов показали, что на бенчмарках, где длинный контекст не так важен — например, MMLU или HumanEval — деградации качества от использования NSA не происходит. На LongBench же NSA показывает качество в среднем на 10% лучше, чем Full Attention. Например, на LCC, где требуется дополнить сниппет кода на основе очень длинного контекста, NSA побеждает 0,232 на 0,163.
Кроме того, есть ощутимый прирост в скорости — вплоть до 9 раз на форварде и 6 раз на бекварде при сравнении с FlashAttention 2. Это стало возможно за счёт эффективного Triton-кернела, кодом которого разработчики не делятся, но в open source уже началась работа по его воспроизведению.
Разбор подготовил❣ Владислав Савинов
Душный NLP
Native Sparse Attention (NSA) — механизм разреженного аттеншена от инженеров из DeepSeek. Утверждается, что NSA имеет качество, сопоставимое с обычным аттеншном на маленьких контекстах, и значительно опережает его на больших — в статье сравнение производится на 64K токенов.
Вместо того чтобы каждый новый query обращался ко всем предыдущим key и value, как это делается в традиционном аттеншне, авторы предлагают сжимать предыдущие ключи и значения в dense-представления. За счёт этого длина последовательности, над которой работает attention, уменьшается, что позволяет работать с контекстом в 64K токенов так, будто их всего 4K. В отличие от предыдущих sparse-методов аттеншна (например, Quest), NSA применяется как при обучении, так и при инференсе.
В статье предлагают три функции для сжатия представления: token compression, token selection и sliding window. Для каждой из них считается аттеншен, а результаты складываются с коэффициентами от MLP-блока.
Token compression предполагает покрытие последовательностей ключей и значений блоками длины 32 с перекрытием по 16 токенов с последующим сжатием каждого блока в «один токен» с помощью MLP с внутриблочным позиционным энкодингом.
На стадии token selection тоже происходит покрытие ключей и значений блоками, но теперь для каждого из них считается скор полезности. После чего выбираются top-16 блоков с максимальным скором. На оставшиеся блоки аттеншн не смотрит, а в выбранных внимание обращается на все ключи и значения.
Авторы отмечают, что в начале обучения сильно доминировали локальные паттерны. Поэтому selection и compression больше фокусировались на последовательностях ближе к текущему токену. В конце, на длинных контекстах, возникали сложности с аттеншеном на начало последовательности. Чтобы решить эту проблему, предлагается дополнительно использовать sliding window для аттеншена на ближайшие 512 токенов.
Метод проверяли на MoE-модели на 27B параметров, из которых 3B — активные. У модели было 30 слоёв аттеншена и 64 головы с разной размерностью. Число экспертов — 72, из них общих — 2. Обучение происходило на 270B токенов с размером контекстного окна в 8K токенов. Далее был SFT с использованием техники YaRN.
Результаты тестов показали, что на бенчмарках, где длинный контекст не так важен — например, MMLU или HumanEval — деградации качества от использования NSA не происходит. На LongBench же NSA показывает качество в среднем на 10% лучше, чем Full Attention. Например, на LCC, где требуется дополнить сниппет кода на основе очень длинного контекста, NSA побеждает 0,232 на 0,163.
Кроме того, есть ощутимый прирост в скорости — вплоть до 9 раз на форварде и 6 раз на бекварде при сравнении с FlashAttention 2. Это стало возможно за счёт эффективного Triton-кернела, кодом которого разработчики не делятся, но в open source уже началась работа по его воспроизведению.
Разбор подготовил
Душный NLP