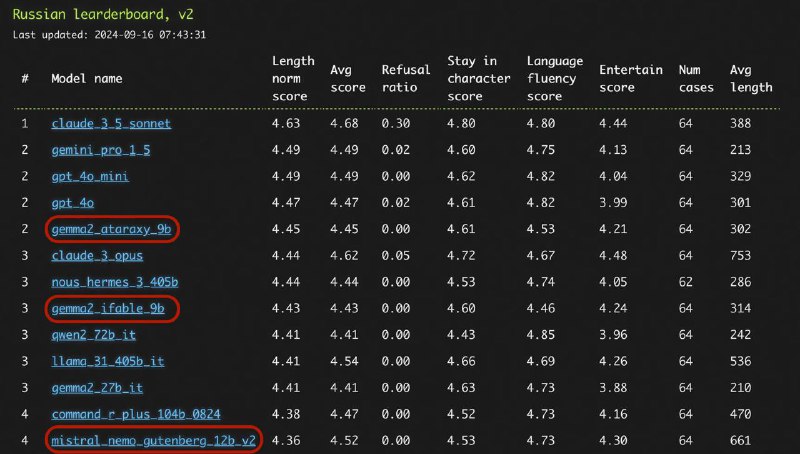
Что особенного в выделенных моделях? Почему они так высоко при таком маленьком размере? Есть ли у них что-то общее?
Оказывается, у них у всех два общих элемента в разных комбинациях: SimPO метод и Гутенберг-DPO датасет.
Начнём с датасета. Берём книжки в публичном доступе. Разбиваем их на фрагменты. Для каждого фрагмента пишем промпт, по которому фрагмент должен генерироваться языковой моделькой, и выжимку. После этого на основе промпта текущего фрагмента и выжимки предыдущего фрагмента моделькой пишем новую синтетическую версию фрагмента.
Полученные синтетические версии используем как негативные примеры, оригинальные фрагменты — как позитивные примеры.
Таким способом мы отучиваем модель писать сухие тексты, и учим нормальному языку. Если кто-то хочет такое же сделать для русского — пишите, я не уверен, что у меня хвтатит времени.
Второй же элемент — вариация DPO с отступом, с наградой, близкой к правдоподобию, с нормализацией по длине, и без необходимости в хранении копии модели. Не уверен, что это играет значимую роль, но SimPO использовался во всех 3 моделях.
Оказывается, у них у всех два общих элемента в разных комбинациях: SimPO метод и Гутенберг-DPO датасет.
Начнём с датасета. Берём книжки в публичном доступе. Разбиваем их на фрагменты. Для каждого фрагмента пишем промпт, по которому фрагмент должен генерироваться языковой моделькой, и выжимку. После этого на основе промпта текущего фрагмента и выжимки предыдущего фрагмента моделькой пишем новую синтетическую версию фрагмента.
Полученные синтетические версии используем как негативные примеры, оригинальные фрагменты — как позитивные примеры.
Таким способом мы отучиваем модель писать сухие тексты, и учим нормальному языку. Если кто-то хочет такое же сделать для русского — пишите, я не уверен, что у меня хвтатит времени.
Второй же элемент — вариация DPO с отступом, с наградой, близкой к правдоподобию, с нормализацией по длине, и без необходимости в хранении копии модели. Не уверен, что это играет значимую роль, но SimPO использовался во всех 3 моделях.