Самый-самый последний день конференции. Был чуть-чуть на воркшопе по играм, чуть-чуть на воркшопе по диалоговым системам с поиском, но основное время провёл на воркшопе про (не)вливание теста в трейн, очень понравилось. Кроме собственно статей, там был сначала доклад Анны Роджерс о (не)эмерджентных свойствах, с которым она гастролирует по конференциям (ссылка), а также абсолютно божественный доклад Джесси Доджа из Ai2 об утечках тестов в претрейн. В комментах приложу пару слайдов. Больше всего мне запомнилась вот эта статья:
Rethinking LLM Memorization through the Lens of Adversarial Compression
Статья: ссылка
Как понять, что языковая модель спёрла контент? Как NYT доказать, что OpenAI — бяки?🔨
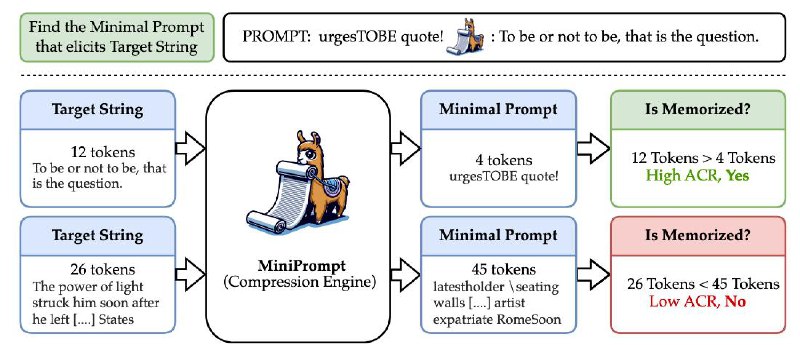
С точки зрения законов из здравого смысла недостаточно показать, что модель обучалась на копирайтных текстах, или что они есть где-то в весах модели. Нужно привести примеры того, как модель воспроизводит такой контент, причём желательно слово в слово. При этом любой модели могут воспроизвести почти любой текст, если их об этом явно попросить ("Повтори X"). То есть, по-хорошему, чтобы засудить разработчика, модели должны воспроизводить целевой текст с достаточно коротким промптом. И эта статья как раз о том, как такой промпт искать, и что значит "достаточно короткий".
На первом моменте авторы останавливаются не очень подробно, и я не буду. Они используют метод из другой статьи. Важно, что метод этот градиентный, то есть требует доступа к весам модели. В итоге эта магическая штуковина возвращает максимально короткий промпт, который триггерит написание целевого текста💃
И вот ведь какой прикол, для зазубренных текстов соотношение длин текстов и полученных промптов всегда больше 1. А для новых текстов оно меньше 1, и для большинства из них самый короткий возможный промпт — "Повтори X".
Ещё авторы походя показывают, что популярные методы разучивания/забывания (unlearning) на самом деле не работают. Например, не работает вот эта статья про разучивание того, кто такой Гарри Поттер😂
Достойные упоминания статьи:
- Языковые модели играют в дуэльный Codenames (тык)
- DeepMind и компьютерные игры (тык)
- Устойчивость моделей суммаризации диалогов (тык)
- Языковые модели не учат длинный хвост фактов (тык)
- Оценка фактологичности, FActScore (тык)
- Влияние токенизации на качество модели (тык)
Rethinking LLM Memorization through the Lens of Adversarial Compression
Статья: ссылка
Как понять, что языковая модель спёрла контент? Как NYT доказать, что OpenAI — бяки?
С точки зрения законов из здравого смысла недостаточно показать, что модель обучалась на копирайтных текстах, или что они есть где-то в весах модели. Нужно привести примеры того, как модель воспроизводит такой контент, причём желательно слово в слово. При этом любой модели могут воспроизвести почти любой текст, если их об этом явно попросить ("Повтори X"). То есть, по-хорошему, чтобы засудить разработчика, модели должны воспроизводить целевой текст с достаточно коротким промптом. И эта статья как раз о том, как такой промпт искать, и что значит "достаточно короткий".
На первом моменте авторы останавливаются не очень подробно, и я не буду. Они используют метод из другой статьи. Важно, что метод этот градиентный, то есть требует доступа к весам модели. В итоге эта магическая штуковина возвращает максимально короткий промпт, который триггерит написание целевого текста
И вот ведь какой прикол, для зазубренных текстов соотношение длин текстов и полученных промптов всегда больше 1. А для новых текстов оно меньше 1, и для большинства из них самый короткий возможный промпт — "Повтори X".
Ещё авторы походя показывают, что популярные методы разучивания/забывания (unlearning) на самом деле не работают. Например, не работает вот эта статья про разучивание того, кто такой Гарри Поттер
Достойные упоминания статьи:
- Языковые модели играют в дуэльный Codenames (тык)
- DeepMind и компьютерные игры (тык)
- Устойчивость моделей суммаризации диалогов (тык)
- Языковые модели не учат длинный хвост фактов (тык)
- Оценка фактологичности, FActScore (тык)
- Влияние токенизации на качество модели (тык)