Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning
Статья: ссылка
Что такое Chain-of-Thought объяснять не буду. Ну ладно, буду💀
Это когда вы заставляете модель сначала генерировать пошаговое объяснение ответа. Можно это делать в zero-shot варианте ("Распиши решение по шагам"), можно во few-shot варианте, и тогда вы должны показать пример такого рассуждения. Можно ещё прямо дописывать "Вот решение по шагам:" к ответу, если есть возможность.
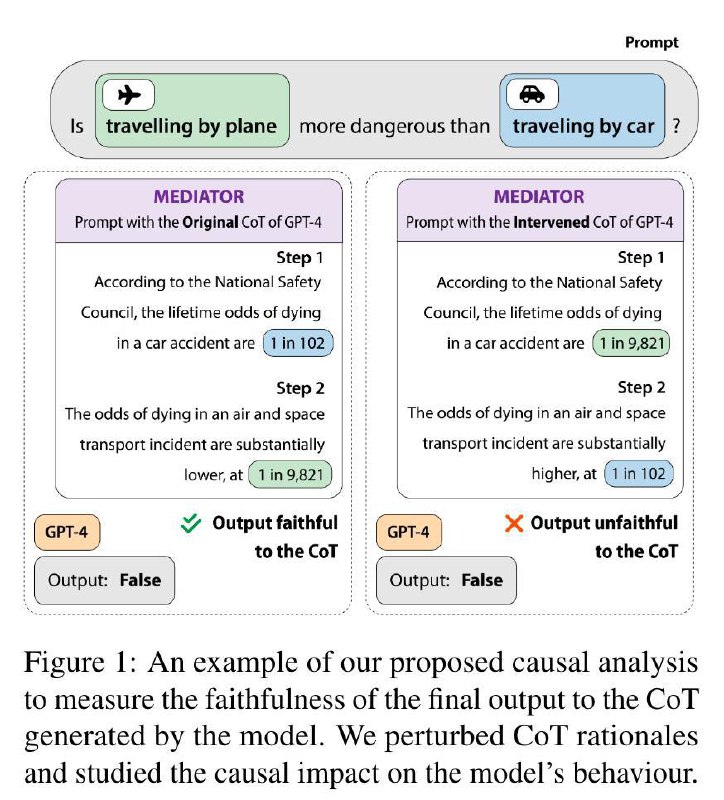
🧑🏫 Первая часть этой статьи про замер того, насколько модели полагаются на это объяснение при генерации финального ответа. На ответ могут влиять две вещи: собственно сам вопрос и объяснение. На объяснение при этом влияет и сам вопрос тоже. Чтобы измерить эффекты, сначала меняем сам вопрос (x0 -> x1), потом соответствующим образом меняем объяснение (r0 -> r1).
Прямой эффект: как изменился ответ при x0 -> x1 при фиксированном объяснении r0.
Непрямой эффект: как изменился ответ при r0 -> r1 при фиксированном входе x0.
Если объяснение реально влияет на ответ, непрямой эффект будет выше прямого.
В качестве датасетов авторы используют StrategyQA (QA с рассуждениями), GSM8k (математика), а также набор сетов на понимание причин и следствий. В статье я не нашёл чиселку для людей, но в презентации было про 95 пунктов непрямого эффекта для них. Для сравнения, GPT-4 выдала 40 пунктов на первом сете, то есть в большом числе случаев она игнорирует объяснение (пусть и неверное)💀
Есть и второй эксперимент с локальными моделями и объяснением от GPT-4, которое по идее должно было положительно влиять на долю правильных ответов, но зачастую игнорировалось.
🤴 Вторая же часть статьи про то, как улучшить модели в связи с этим эффектом. И тут многоходовочка: генерируем объяснения умной моделью, а также их версии на основе неправильных входов. Дальше делаем SFT на правильных версиях, а потом DPO на парах правильных и неправильных версий. Ну и в конце полируем хитрым лоссом с компонентной штрафа за ответ на неправильное объяснение. DPO нам обеспечивает нормальный CoT, а хитрый лосс — нормальный ответ.
Результат: значительные плюсики на всех метриках по сравнению с просто SFT или SFT + CoT, то есть победа☺️
Статья: ссылка
Что такое Chain-of-Thought объяснять не буду. Ну ладно, буду
Это когда вы заставляете модель сначала генерировать пошаговое объяснение ответа. Можно это делать в zero-shot варианте ("Распиши решение по шагам"), можно во few-shot варианте, и тогда вы должны показать пример такого рассуждения. Можно ещё прямо дописывать "Вот решение по шагам:" к ответу, если есть возможность.
Прямой эффект: как изменился ответ при x0 -> x1 при фиксированном объяснении r0.
Непрямой эффект: как изменился ответ при r0 -> r1 при фиксированном входе x0.
Если объяснение реально влияет на ответ, непрямой эффект будет выше прямого.
В качестве датасетов авторы используют StrategyQA (QA с рассуждениями), GSM8k (математика), а также набор сетов на понимание причин и следствий. В статье я не нашёл чиселку для людей, но в презентации было про 95 пунктов непрямого эффекта для них. Для сравнения, GPT-4 выдала 40 пунктов на первом сете, то есть в большом числе случаев она игнорирует объяснение (пусть и неверное)
Есть и второй эксперимент с локальными моделями и объяснением от GPT-4, которое по идее должно было положительно влиять на долю правильных ответов, но зачастую игнорировалось.
Результат: значительные плюсики на всех метриках по сравнению с просто SFT или SFT + CoT, то есть победа