Пара статей с воркшопов отдельными постами, для них важны картинки.
Evaluating Vision-Language Models on Bistable Images
Статья: ссылка
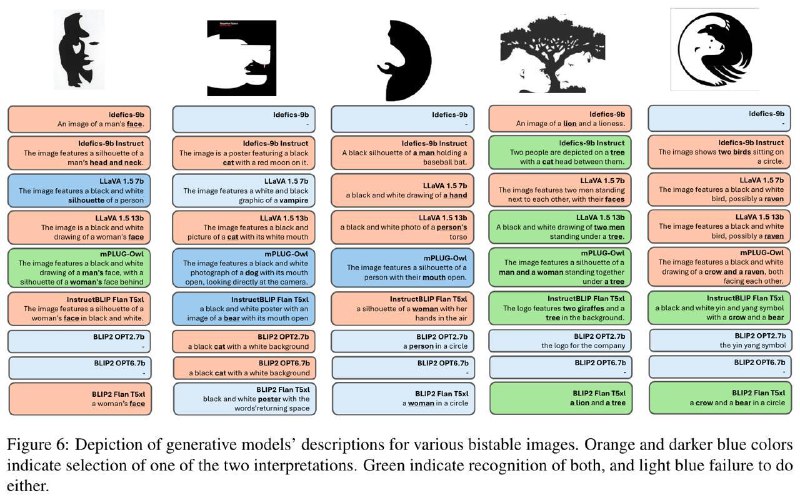
Двойственные изображения — это особый тип оптических иллюзий, которые можно воспринимать двумя различными способами. Обратите внимание на приложенный скриншот, при некотором напряжении каждому изображению можно дать две интерпретации. Центральный вопрос статьи — как такие картинки воспринимают контрастивные модели типа CLIP'а и генеративные модели типа LLaVA?
Для начала собираем датасет, 29 двойственных изображений. Для каждого изображения создаём 116 аугментаций, меняя яркость или оттенки и применяя повороты. Для энкодеров подаём на вход несколько текстовых интерпретаций и считаем близость к картинке, для генеративных моделей считаем лосс на таких же интерпретациях.
Как оказалось, модели обычно явно предпочитают одну из интерпретаций, как и люди. Между моделями различия есть в основном между разными архитектурами, даже если они обучались на одних и тех же данных. Аугментации картинок практически ничего не меняют, зато аугментации текстов оказывают значительный эффект. Если сравнивать с первым порывом людей, никакой корреляции нет, модели больше чем в половине случаев выбрали другую интерпретацию.
Выводы? Да чёрт его знает😐
Похоже, что текущие модели совсем нечеловечески воспринимают картинки. И если каким-то вещам типа эстетичности их можно научить, то для более тонких штук скорее всего потребуются более тонкие данные.
Evaluating Vision-Language Models on Bistable Images
Статья: ссылка
Двойственные изображения — это особый тип оптических иллюзий, которые можно воспринимать двумя различными способами. Обратите внимание на приложенный скриншот, при некотором напряжении каждому изображению можно дать две интерпретации. Центральный вопрос статьи — как такие картинки воспринимают контрастивные модели типа CLIP'а и генеративные модели типа LLaVA?
Для начала собираем датасет, 29 двойственных изображений. Для каждого изображения создаём 116 аугментаций, меняя яркость или оттенки и применяя повороты. Для энкодеров подаём на вход несколько текстовых интерпретаций и считаем близость к картинке, для генеративных моделей считаем лосс на таких же интерпретациях.
Как оказалось, модели обычно явно предпочитают одну из интерпретаций, как и люди. Между моделями различия есть в основном между разными архитектурами, даже если они обучались на одних и тех же данных. Аугментации картинок практически ничего не меняют, зато аугментации текстов оказывают значительный эффект. Если сравнивать с первым порывом людей, никакой корреляции нет, модели больше чем в половине случаев выбрали другую интерпретацию.
Выводы? Да чёрт его знает
Похоже, что текущие модели совсем нечеловечески воспринимают картинки. И если каким-то вещам типа эстетичности их можно научить, то для более тонких штук скорее всего потребуются более тонкие данные.