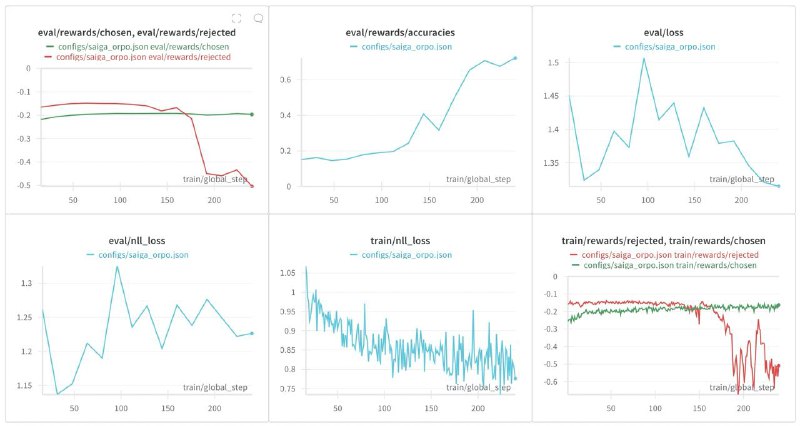
Пока ORPO не завелось. Причём технически всё неплохо, модель выучивает предпочтения, и её в целом не разносит. Но в итоге SbS далеко не выигрывается.
Дело тут скорее всего вот в чём: я не использовал реальные предпочтения. Они у меня есть только для тест-сета, и учиться на тест-сете не очень хочется. Вместо этого я сегенрировал текущей SFT моделью отрициательные варианты, а качестве положительных взял ответы GPT-4.
Где бы раздобыть реальные предпочтения, не тратя кучу денег? Переводы не предлагать.
Дело тут скорее всего вот в чём: я не использовал реальные предпочтения. Они у меня есть только для тест-сета, и учиться на тест-сете не очень хочется. Вместо этого я сегенрировал текущей SFT моделью отрициательные варианты, а качестве положительных взял ответы GPT-4.
Где бы раздобыть реальные предпочтения, не тратя кучу денег? Переводы не предлагать.