Полез перечитывать блог OpenAI про эмбеддинг-модель (да, такое тоже есть, embeddings-as-a-service). После чего заглянул в документацию - посмотреть расценки, может, ещё чего интересного нашёл бы. И вы не поверите - нашёл.
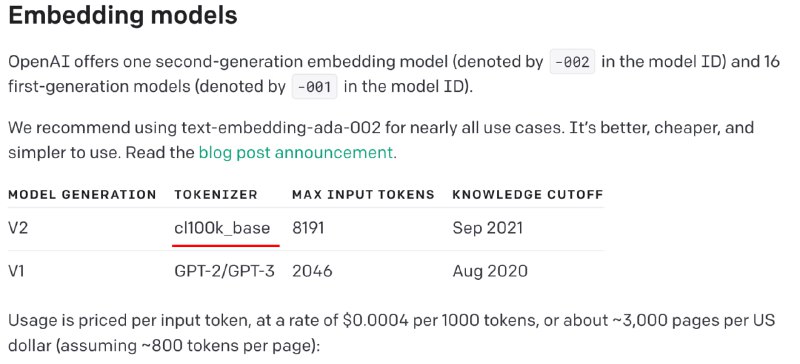
Для свежей модели, выпущенной в середине декабря 2022го, используется новый токенайзер с названием
И да, там этот токенайзер можно загрузить, поизучать словарь. Что хочется отметить:
- как следует из названия, в словаре 100k токенов (100,277, если быть точным). В GPT2/3/3.5 в словаре было ~50k токенов, к слову. Это значит, что в среднем длина последовательности закодированных токенов для обработки моделью будет меньше. А вот это приводит к ускорению инференса (сильному или нет - оценить сложно). Ждем в GPT-N+1 :)
- в словаре ровно 1110 токенов, являющихся цифровыми: 10 однозначных, 100 двузначных (включая "01", для дат), 1000 трёхзначных. В теории, это может помочь модели точнее писать даты, решать математику - ну и в целом избегать путаницы. Кек в том, что токенизация идёт слева направо, и миллион будет делиться на токены 100|000|0, а не 1|000|000. Это неудобно для разрядных операций ("прибавь тыщу"), да и в целом немного контр-интуитивно;
- это base словарь :) может быть существует advanced/large для новой модели, будем посмотреть.
Интересно ещё и то, что вечером мне на глаза попался пост про обучение модели со словарём в миллион токенов для мультиязычных моделей. Но это не просто словарь, а хитро собранный, с эвристиками для оптимальной работы на разных языках. Почитать краткое описание можно вот в этом посте: тык
Для свежей модели, выпущенной в середине декабря 2022го, используется новый токенайзер с названием
cl100k_base (см. изображение). В целом, ничего нового, если два месяца назад вы не пропустили релиз в опенсорс библиотеки tiktoken от OpenAI, которая как раз предоставляет токенайзеры для некоторых моделей - в ней этот словарь есть, описан в документации и упоминается в примерах. Фишка в том, что реализации из этой библиотеки лучше параллелятся и работают быстрее HuggingFace'овских. И да, там этот токенайзер можно загрузить, поизучать словарь. Что хочется отметить:
- как следует из названия, в словаре 100k токенов (100,277, если быть точным). В GPT2/3/3.5 в словаре было ~50k токенов, к слову. Это значит, что в среднем длина последовательности закодированных токенов для обработки моделью будет меньше. А вот это приводит к ускорению инференса (сильному или нет - оценить сложно). Ждем в GPT-N+1 :)
- в словаре ровно 1110 токенов, являющихся цифровыми: 10 однозначных, 100 двузначных (включая "01", для дат), 1000 трёхзначных. В теории, это может помочь модели точнее писать даты, решать математику - ну и в целом избегать путаницы. Кек в том, что токенизация идёт слева направо, и миллион будет делиться на токены 100|000|0, а не 1|000|000. Это неудобно для разрядных операций ("прибавь тыщу"), да и в целом немного контр-интуитивно;
- это base словарь :) может быть существует advanced/large для новой модели, будем посмотреть.
Интересно ещё и то, что вечером мне на глаза попался пост про обучение модели со словарём в миллион токенов для мультиязычных моделей. Но это не просто словарь, а хитро собранный, с эвристиками для оптимальной работы на разных языках. Почитать краткое описание можно вот в этом посте: тык