Интересное про эту модель:
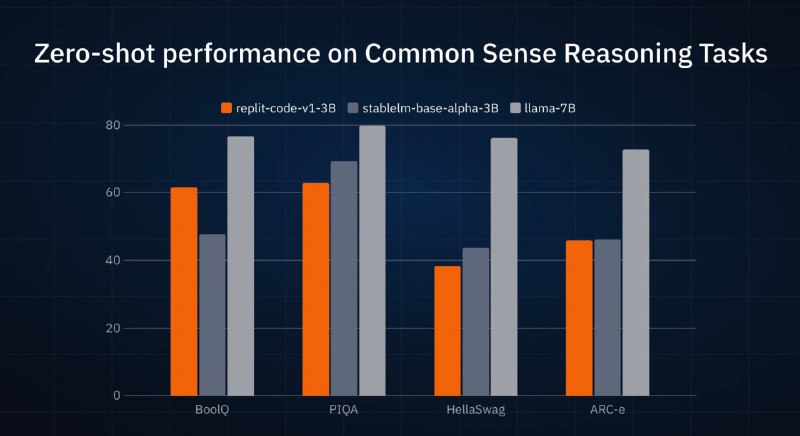
— как я написал, модель тренировалась на коде, но при этом показывает адекватное качество на разных бенчмарках для языковых моделей (картинка 1). В некоторых - сравнима или превосходит недавно релизнутые StableLM от компании Stability (это те, которые StableDiffusion делают), которые тренировались в превычном режиме.
— модель лучше всех остальных открытых на бенчмарке HumanEval для написания функций/кода от OpenAI (был разработан для оценки первой кодовой модели Codex, которая легла в основу Copilot) - картинка 2.
— более того, она превосходит по качеству сам оригинальный Codex, при том что сама в 5 раз меньше
— я ошибся в посте выше, нашел, что обещают релиз на следующей неделе. Будет лицензия CC BY-SA 4.0 (разрешает коммерческое использование)
— в AI-команде Repl.it всего ДВА человека работает, и вот они потянули обучение такой модели, подготовку к выкатке. Вот это эффективность - многим командам остается только завидовать! (маленьким шрифтом: один из них был Head of Applied Research в Google, но всё же..)
— модель тренировали на 525B токенов. Чем это примечательно? В прошлом году компанией Google был проведён анализ оптимальности тренировки моделей, какое должно быть соотношение между объемом данных и размером модели. Иногда лучше сделать модель поменьше, если данных не так много, чтобы это было эффективнее с точки зрения затраченных ресурсов. Подробнее про это тут. Так вот, 525B токенов для 2.7B модели - это примерно в 20 раз больше оптимального, то есть модель прям утюнили по самое никуда, впихнув максимально возможное количество знаний. Это не очень эффективно с точки зрения ресурсов на обучение (можно было сделать модель больше, и потратить меньше ресурсов для достижения такого же качества), НО! зато это ОЧЕНЬ эффективно при применении модели, так как гонять 2.7B параметров куда проще, чем 10B. В общем, крутой тренд!
Как здорово, когда есть данные, на которых можно потренироваться...а ведь говорили еще на заре BigData-эры: сохраняйте всё, что можете! Пригодится!
— как я написал, модель тренировалась на коде, но при этом показывает адекватное качество на разных бенчмарках для языковых моделей (картинка 1). В некоторых - сравнима или превосходит недавно релизнутые StableLM от компании Stability (это те, которые StableDiffusion делают), которые тренировались в превычном режиме.
— модель лучше всех остальных открытых на бенчмарке HumanEval для написания функций/кода от OpenAI (был разработан для оценки первой кодовой модели Codex, которая легла в основу Copilot) - картинка 2.
— более того, она превосходит по качеству сам оригинальный Codex, при том что сама в 5 раз меньше
— я ошибся в посте выше, нашел, что обещают релиз на следующей неделе. Будет лицензия CC BY-SA 4.0 (разрешает коммерческое использование)
— в AI-команде Repl.it всего ДВА человека работает, и вот они потянули обучение такой модели, подготовку к выкатке. Вот это эффективность - многим командам остается только завидовать! (маленьким шрифтом: один из них был Head of Applied Research в Google, но всё же..)
— модель тренировали на 525B токенов. Чем это примечательно? В прошлом году компанией Google был проведён анализ оптимальности тренировки моделей, какое должно быть соотношение между объемом данных и размером модели. Иногда лучше сделать модель поменьше, если данных не так много, чтобы это было эффективнее с точки зрения затраченных ресурсов. Подробнее про это тут. Так вот, 525B токенов для 2.7B модели - это примерно в 20 раз больше оптимального, то есть модель прям утюнили по самое никуда, впихнув максимально возможное количество знаний. Это не очень эффективно с точки зрения ресурсов на обучение (можно было сделать модель больше, и потратить меньше ресурсов для достижения такого же качества), НО! зато это ОЧЕНЬ эффективно при применении модели, так как гонять 2.7B параметров куда проще, чем 10B. В общем, крутой тренд!
Как здорово, когда есть данные, на которых можно потренироваться...а ведь говорили еще на заре BigData-эры: сохраняйте всё, что можете! Пригодится!