Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study
Думаю, многие знают, что с точки зрения предоставления фактической информации GPT-модели могут чудить. GPT-4 достаточно редко врёт (субъективно), особенно если давать ей контекст, из которого можно "прочитать" и выдать ответ. Всё это приводит к достаточно логичному выводу: надо использовать внешнюю систему (типа Google или Bing), чтобы находить потенциально информацию и добавлять её в промпт - а там уже модель сама разберется. Процесс поиска нужных кусков текста называется Retrieve.
Но выходит какая-то странная вещь: с одной стороны мы никак не тренируем модели на это, только учим предсказывать следующее слово, а с другой - хотим их так применять. В мире машинного обучения такая путаница обычно ведёт к деградации качества, порой, существенного (но с LLM это почти незаметно).
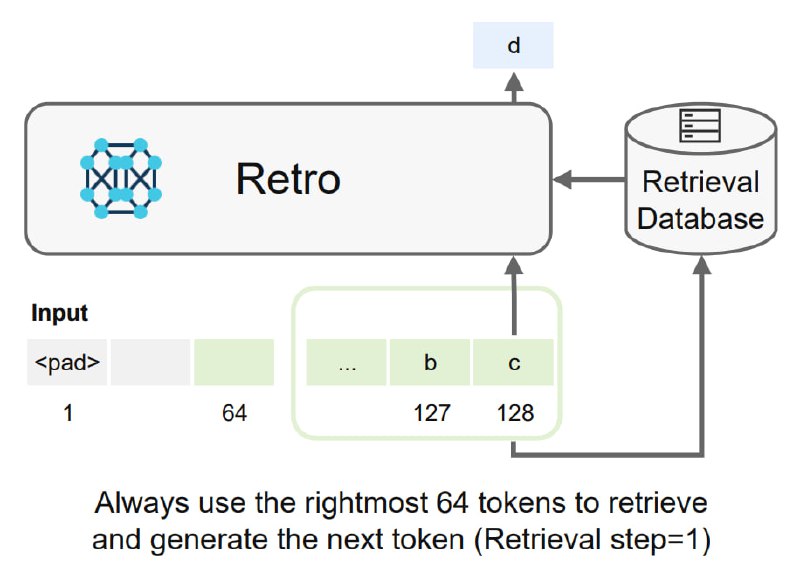
Однако уже есть модели, которые прямо из коробки "подключаются" к большой базе знаний, чтобы из неё находить качественные данные прямо во время генерации текста. Я про них даже делал две лекции в 2022м году - вот, это есть в закреплённом сообщении в канале:
— Лекция про языковые модели, основанные на принципе поиска ближайших соседей: часть 1, часть 2 (понятно будет даже если вы не занимаетесь NLP)
Наконец, перехожу к сегодняшней статье: авторы проводят исследования, как такая тренировка модели (та, что во второй части лекции выше) влияет на качество. Оказывается, что рост метрик наблюдается не везде - но для задач вопросов-ответов буст существенный, что ожидаемо.
Мне кажется странным название статьи, так как это не очень похоже на Comprehensive Study, но тем не менее. Очень жду, когда к LLM-кам припахают графы знаний!
(да, этот пост написан исключительно для того, чтобы вы проверили закреп и посмотрели лекции, чтобы понять, про что речь)
Думаю, многие знают, что с точки зрения предоставления фактической информации GPT-модели могут чудить. GPT-4 достаточно редко врёт (субъективно), особенно если давать ей контекст, из которого можно "прочитать" и выдать ответ. Всё это приводит к достаточно логичному выводу: надо использовать внешнюю систему (типа Google или Bing), чтобы находить потенциально информацию и добавлять её в промпт - а там уже модель сама разберется. Процесс поиска нужных кусков текста называется Retrieve.
Но выходит какая-то странная вещь: с одной стороны мы никак не тренируем модели на это, только учим предсказывать следующее слово, а с другой - хотим их так применять. В мире машинного обучения такая путаница обычно ведёт к деградации качества, порой, существенного (но с LLM это почти незаметно).
Однако уже есть модели, которые прямо из коробки "подключаются" к большой базе знаний, чтобы из неё находить качественные данные прямо во время генерации текста. Я про них даже делал две лекции в 2022м году - вот, это есть в закреплённом сообщении в канале:
— Лекция про языковые модели, основанные на принципе поиска ближайших соседей: часть 1, часть 2 (понятно будет даже если вы не занимаетесь NLP)
Наконец, перехожу к сегодняшней статье: авторы проводят исследования, как такая тренировка модели (та, что во второй части лекции выше) влияет на качество. Оказывается, что рост метрик наблюдается не везде - но для задач вопросов-ответов буст существенный, что ожидаемо.
Мне кажется странным название статьи, так как это не очень похоже на Comprehensive Study, но тем не менее. Очень жду, когда к LLM-кам припахают графы знаний!
(да, этот пост написан исключительно для того, чтобы вы проверили закреп и посмотрели лекции, чтобы понять, про что речь)