Пропустил вчера в обзоре достаточно важную вещь, не посчитал её значимой, но понял, что это не так.
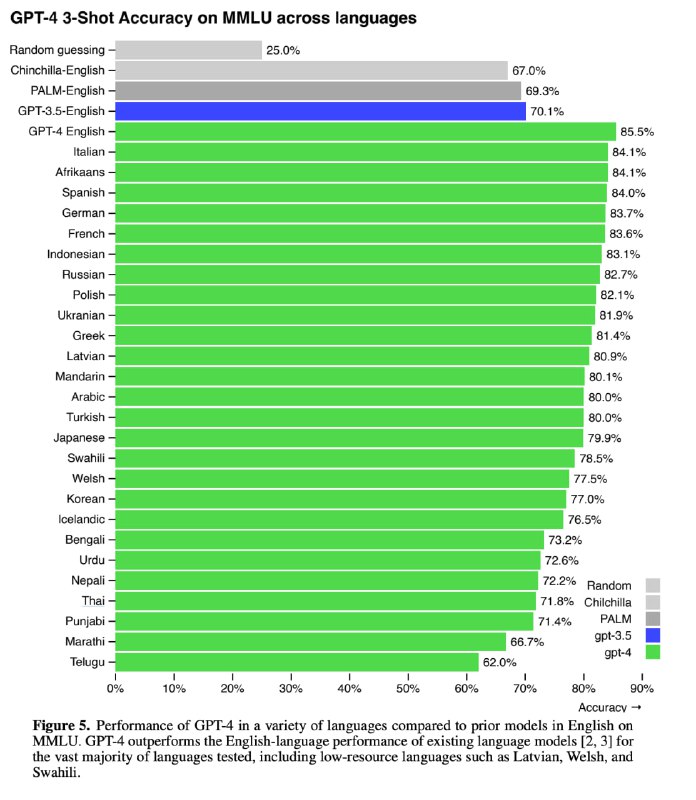
Есть такой датасет MMLU (Massive Multi-task Language Understanding), где собраны вопросы из очень широкого круга тем на понимание языка в разных задачах (57 доменов, математика, биология, право, социальные и гуманитарные науки, итд). Для вопроса есть 4 варианта ответа, один из которых верный. То есть случайное гадание показывает результат в 25% правильных ответов. Примеры вопросов и их сложности см. на второй картинке. Средний человек-разметчик (то есть это не учёный, не профессор - обычный человек, который подрабатывает разметкой) отвечает правильно на ~35% вопросов, однако эксперты коллективно зарешивают +-90% (точную оценку дать сложно).
В оригинале весь датасет на английском языке. А что если вопросы и ответы перевести на другие языки, особенно редкие, не самые распространенные? Будет ли модель на них работать хоть как-то?
Для перевода использовали сервис Microsoft Azure Translate. Переводы не идеальны, в некоторых случаях теряется важная информация, что может отрицательно сказаться на качестве (то есть мы упираемся частично в способности маленькой модельки-переводчика)
GPT-4 не только значительно превосходит существующие модели на английском языке, но и демонстрирует высокие показатели на других языках. В переведенных вариантах MMLU GPT-4 превосходит англоязычный уровень других больших моделей (включая Гугловские) на 24 из 26 рассмотренных языков.
Более того, GPT-4 работает на редких языках лучше, чем ChatGPT работала на английском (та показывала 70.1% качества, а новая модель на тайском языке 71.8%). На английском же показатель на 10% лучше, чем у других моделей - в том числе и у крупнейшей PaLM от Google. Он составляет 86.4%, а я напомню, что коллектив людей-экспертов показывает 90%.
Есть такой датасет MMLU (Massive Multi-task Language Understanding), где собраны вопросы из очень широкого круга тем на понимание языка в разных задачах (57 доменов, математика, биология, право, социальные и гуманитарные науки, итд). Для вопроса есть 4 варианта ответа, один из которых верный. То есть случайное гадание показывает результат в 25% правильных ответов. Примеры вопросов и их сложности см. на второй картинке. Средний человек-разметчик (то есть это не учёный, не профессор - обычный человек, который подрабатывает разметкой) отвечает правильно на ~35% вопросов, однако эксперты коллективно зарешивают +-90% (точную оценку дать сложно).
В оригинале весь датасет на английском языке. А что если вопросы и ответы перевести на другие языки, особенно редкие, не самые распространенные? Будет ли модель на них работать хоть как-то?
Для перевода использовали сервис Microsoft Azure Translate. Переводы не идеальны, в некоторых случаях теряется важная информация, что может отрицательно сказаться на качестве (то есть мы упираемся частично в способности маленькой модельки-переводчика)
GPT-4 не только значительно превосходит существующие модели на английском языке, но и демонстрирует высокие показатели на других языках. В переведенных вариантах MMLU GPT-4 превосходит англоязычный уровень других больших моделей (включая Гугловские) на 24 из 26 рассмотренных языков.
Более того, GPT-4 работает на редких языках лучше, чем ChatGPT работала на английском (та показывала 70.1% качества, а новая модель на тайском языке 71.8%). На английском же показатель на 10% лучше, чем у других моделей - в том числе и у крупнейшей PaLM от Google. Он составляет 86.4%, а я напомню, что коллектив людей-экспертов показывает 90%.