Главное (отсюда):
> прием входных изображений и текста, вывод только текстовый (никакой генерации картинок нет, но умеет их принимать на вход и, например, отвечать на вопросы)
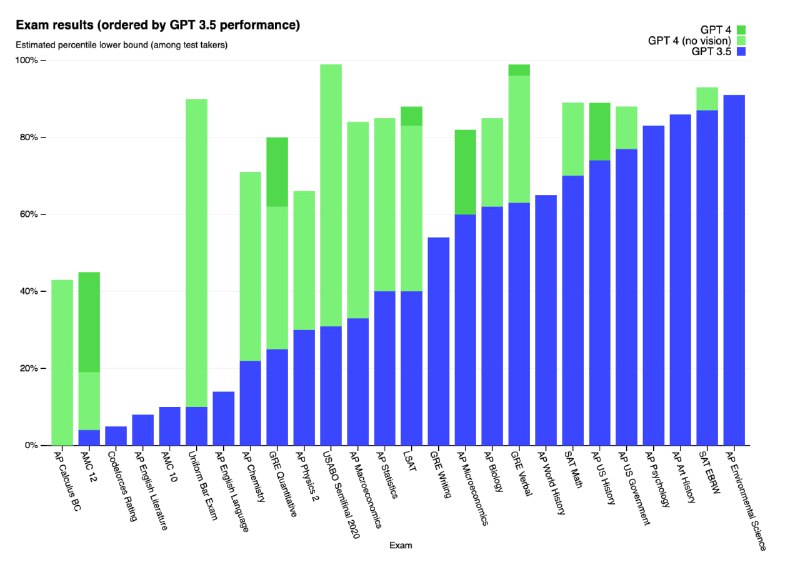
> хуже, чем люди во многих реальных сценариях, но демонстрирует производительность на уровне человека в различных профессиональных и академических тестах (как ChatGPT проходила разные тесты на юриста и доктора)
> например, GPT-4 проходит смоделированный экзамен на адвоката с оценкой около 10% лучших участников теста; оценка GPT-3.5 была около нижних 10%.
> 6 месяцев непрерывной работы над решением алайнмента и обучение из фидбека людей
> очень много работали с инфраструктурой, с оптимизацией, и теперь тренирвока LLMок очень стабильна и предсказуема
> картинки на данный момент не доступны, есть waitlist для текстовой части модели
> прием входных изображений и текста, вывод только текстовый (никакой генерации картинок нет, но умеет их принимать на вход и, например, отвечать на вопросы)
> хуже, чем люди во многих реальных сценариях, но демонстрирует производительность на уровне человека в различных профессиональных и академических тестах (как ChatGPT проходила разные тесты на юриста и доктора)
> например, GPT-4 проходит смоделированный экзамен на адвоката с оценкой около 10% лучших участников теста; оценка GPT-3.5 была около нижних 10%.
> 6 месяцев непрерывной работы над решением алайнмента и обучение из фидбека людей
> очень много работали с инфраструктурой, с оптимизацией, и теперь тренирвока LLMок очень стабильна и предсказуема
> картинки на данный момент не доступны, есть waitlist для текстовой части модели