JUST IN: META обучили семейство моделей LLaMA (7B, 13B, 33B и 65B параметров), однако не всё так просто:
> Access to the model will be granted on a case-by-case basis to academic researchers
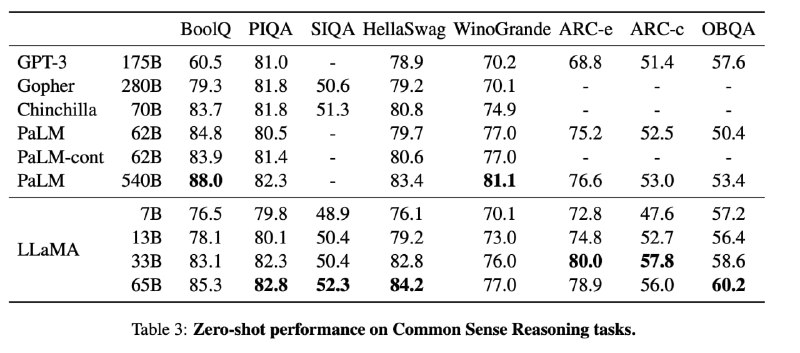
Модель 65B обучена с +- тем же вычислительным бюджетом, что и GPT-3, но на большем количестве токенов (~оптимальном для выхода на плато):
> We trained LLaMA 65B and LLaMA 33B on 1.4 trillion tokens. Our smallest model, LLaMA 7B, is trained on one trillion tokens.
Модели мультиязычные (20 языков в датасете).
Метрики на уровне или чуть лучше, чем у GPT-3, правда я так и не понял, идёт ли сравнение с версией 2020го года или существенно улучшенной GPT-3.5 2022го.
Статья (pdf): ссылка.
> Access to the model will be granted on a case-by-case basis to academic researchers
Модель 65B обучена с +- тем же вычислительным бюджетом, что и GPT-3, но на большем количестве токенов (~оптимальном для выхода на плато):
> We trained LLaMA 65B and LLaMA 33B on 1.4 trillion tokens. Our smallest model, LLaMA 7B, is trained on one trillion tokens.
Модели мультиязычные (20 языков в датасете).
Метрики на уровне или чуть лучше, чем у GPT-3, правда я так и не понял, идёт ли сравнение с версией 2020го года или существенно улучшенной GPT-3.5 2022го.
Статья (pdf): ссылка.