Продолжаю наваливать контенту.
Если проблема актуальна, то понятно, что ею занимаются большое количество независимых групп. Увидел, что по ускорению инференса LLM в очень короткий срок появилось 3-4 работы с почти одинаковыми идеями, при этом работы независимы. Например: раз, два.
В чем, собственно, проблема, и как её решать?
Преимущество трансформеров на обучении заключается в том, что мы "видим" все предыдущие токены (а в будущие для декодеров не смотрим, потому что так устроено маскирование аттеншена). Однако во время предсказания (инференса) подобное распараллеливание невозможно, поскольку, к примеру, при генерации 5го токена мы не знаем 4й, если его не сгенерируем. Поэтому делаем сначала 1й, потом 2й, и так итеративно до конца, по одному за раз. Но что, если бы вы смогли угадать предыдущие токены, и сразу скакать на 2-3-4 вперёд?
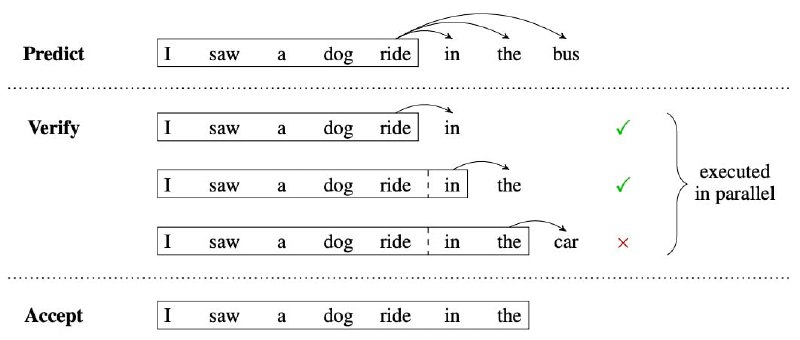
В приведенных выше статьях предлагаются различные способы "угадывания" предыдущих токенов, такие как использование модели меньшего размера (не LLM, а просто LM, хы). Важно то, что мы можем использовать LLM, чтобы параллельно проверить, какие из угаданных токенов верны, и принять те, с которыми соглашается LLM (см. картинку с примером).
Мне почему-то это напомнило механизм предсказания переходов в процессорах, когда второй поток в ядре начинает что-то считать, при том не зная, потребуется ли это (но пытается угадать). Про процессоры можно почитать вот тут, ООООЧЕНЬ интересное чтиво.
Если проблема актуальна, то понятно, что ею занимаются большое количество независимых групп. Увидел, что по ускорению инференса LLM в очень короткий срок появилось 3-4 работы с почти одинаковыми идеями, при этом работы независимы. Например: раз, два.
В чем, собственно, проблема, и как её решать?
Преимущество трансформеров на обучении заключается в том, что мы "видим" все предыдущие токены (а в будущие для декодеров не смотрим, потому что так устроено маскирование аттеншена). Однако во время предсказания (инференса) подобное распараллеливание невозможно, поскольку, к примеру, при генерации 5го токена мы не знаем 4й, если его не сгенерируем. Поэтому делаем сначала 1й, потом 2й, и так итеративно до конца, по одному за раз. Но что, если бы вы смогли угадать предыдущие токены, и сразу скакать на 2-3-4 вперёд?
В приведенных выше статьях предлагаются различные способы "угадывания" предыдущих токенов, такие как использование модели меньшего размера (не LLM, а просто LM, хы). Важно то, что мы можем использовать LLM, чтобы параллельно проверить, какие из угаданных токенов верны, и принять те, с которыми соглашается LLM (см. картинку с примером).
Мне почему-то это напомнило механизм предсказания переходов в процессорах, когда второй поток в ядре начинает что-то считать, при том не зная, потребуется ли это (но пытается угадать). Про процессоры можно почитать вот тут, ООООЧЕНЬ интересное чтиво.