Tuning computer vision models with task rewards
Теперь и ребята из CV догоняют NLP, тренируя модели с помощью RL-методов (вон сколько кейвордов в одном предложении!)
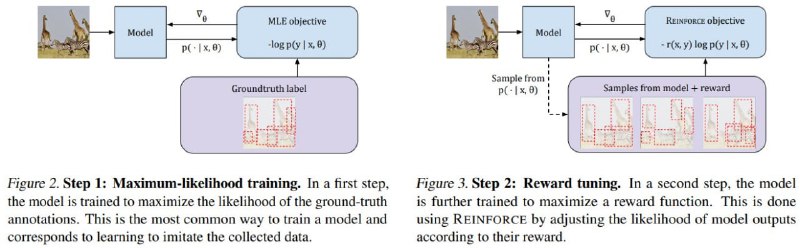
Используют метод REINFORCE (👴 ). CV-моделька, как и RL-агенты, учится «действовать», а затем «критикует» результаты. Тюнят для Object Detection (привед YoLO 10?), и это бустит Recall/mAP. Также решается panoptic segmentation, чтобы предсказывать более однородные/согласованные маски для объектов.
Теперь и ребята из CV догоняют NLP, тренируя модели с помощью RL-методов (вон сколько кейвордов в одном предложении!)
Используют метод REINFORCE (