🚀 @SBERLOGASCI webinar on data science:
👨🔬 Obozov M.A. "Proximal Policy Optimization. От графов Кэли до RLHF."
⌚️ Пятница 14 июня 19.00 по Москве
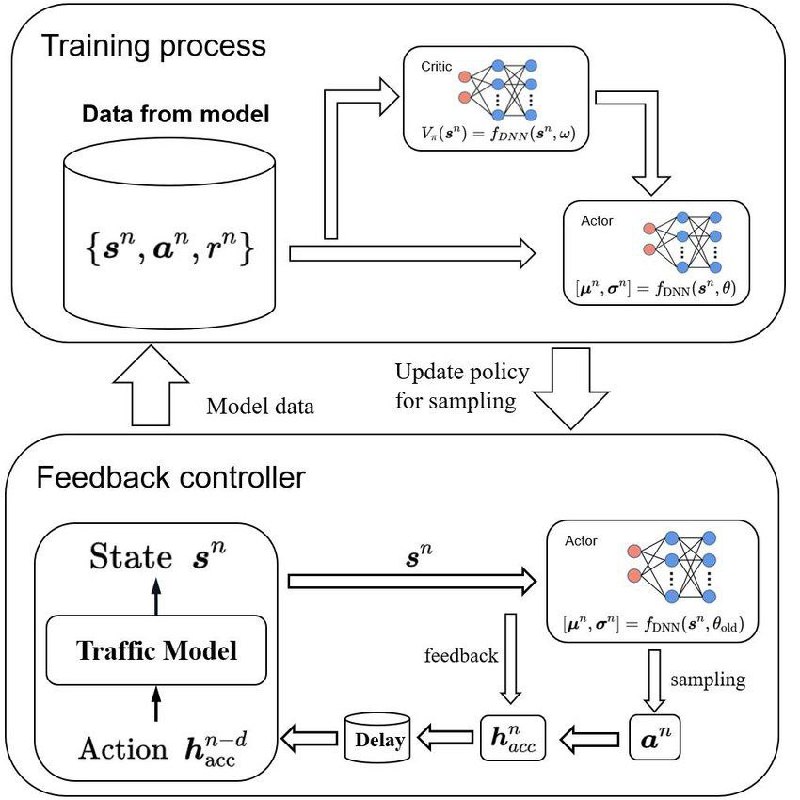
PPO - достаточно современный и интересный Policy Gradient метод, который базируется на идее клиппинга и обучение policy network с специальной целевой функцией. Концептуально алгоритм решает проблему больших policy обновлений, что значительно улучшает сходимость. При этом его применение часто очень нетривиально, а понимание алгоритма к сожалению нередко заканчивается абстрактными идеями и просто знанием об его существование. Данная лекция ориентирована на исправление этой проблемы.
Всего лекция состоит из четырёх частей:
1. Пользовательское понимание PPO, концепции и основные идеи, отличие от REINFORCE и других PGM.
2. Более глубокое понимание и описание математики стоящей за этим алгоритмом.
3. Применение к реальным задачам в том числе и к графовым.
4. RLHF с PPO. Эта часть ориентирована именно на LLM инженеров.
📖 Presentation: https://t.me/sberlogasci/11995/14677
📹 Video: https://youtu.be/CN72nLjpmuk?si=ue-te9oh8VyFOqhP
Доп материалы:
https://arxiv.org/abs/1707.06347
https://arxiv.org/abs/2307.04964
https://arxiv.org/abs/2401.06080
https://github.com/OpenLLMAI/OpenRLHF
https://openai.com/index/openai-baselines-ppo/
https://www.arxiv.org/abs/2405.04664
https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo
Zoom link will be in @sberlogabig just before start. Video records: https://www.youtube.com/c/SciBerloga - subscribe
👨🔬 Obozov M.A. "Proximal Policy Optimization. От графов Кэли до RLHF."
⌚️ Пятница 14 июня 19.00 по Москве
PPO - достаточно современный и интересный Policy Gradient метод, который базируется на идее клиппинга и обучение policy network с специальной целевой функцией. Концептуально алгоритм решает проблему больших policy обновлений, что значительно улучшает сходимость. При этом его применение часто очень нетривиально, а понимание алгоритма к сожалению нередко заканчивается абстрактными идеями и просто знанием об его существование. Данная лекция ориентирована на исправление этой проблемы.
Всего лекция состоит из четырёх частей:
1. Пользовательское понимание PPO, концепции и основные идеи, отличие от REINFORCE и других PGM.
2. Более глубокое понимание и описание математики стоящей за этим алгоритмом.
3. Применение к реальным задачам в том числе и к графовым.
4. RLHF с PPO. Эта часть ориентирована именно на LLM инженеров.
📖 Presentation: https://t.me/sberlogasci/11995/14677
📹 Video: https://youtu.be/CN72nLjpmuk?si=ue-te9oh8VyFOqhP
Доп материалы:
https://arxiv.org/abs/1707.06347
https://arxiv.org/abs/2307.04964
https://arxiv.org/abs/2401.06080
https://github.com/OpenLLMAI/OpenRLHF
https://openai.com/index/openai-baselines-ppo/
https://www.arxiv.org/abs/2405.04664
https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo
Zoom link will be in @sberlogabig just before start. Video records: https://www.youtube.com/c/SciBerloga - subscribe