🚀 @SBERLOGABIG webinar on data science:
👨🔬 Никита Бухал "Анализ feature importances - 1"
⌚️ 20 March, Monday, 20.00 (Moscow Time)
❗️Нестандартный день, время
Add to Google Calendar
Есть множество методов определения feature importances - большинство из них не идеальны. Мы начнем серию рассказов об этом вопросе.
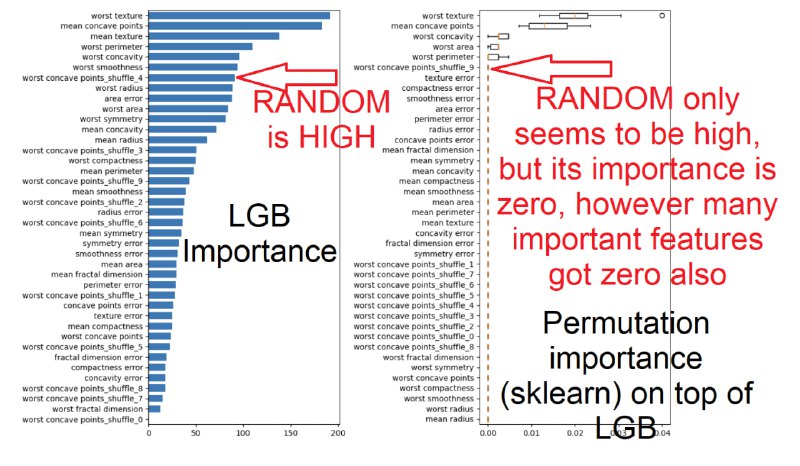
1) Даже если фича высока по импортансу - это не гарантирует, что она реальна важна. Эксперимент - добавляем рандомные фичи смотрим их позицию, оказывается часто она достаточно высока.
2) Если фича низка по импортансу - эта НЕ означает, что она не важна. Основная проблема - избыточные фичи - "redundant" - (часто высоко-коррелированные). То есть фича сама по себе неплоха, но другие лучше, и модель выбирает их, а эта идет в конец.
Разные модели работают по разному - LGB, Лассо - обычно выбирают лишь одну фичу, а другие имеют низкий импортанс, а Ридж, Random Forest часто "расплавляют" импортанс - то есть все схожие фичи получают примерно равную долю импортанса - исходный импортанс примерно делится на число элементов группы. Если группа велика - импортанс каждого представителя мал - это создает ложное впечатление, что фича не важна. Эксперимент - добавляем дубликаты к фичам, смотрим что происходит.
В докладе будут рассказаны первые результаты подобных экспериментов. Примеры в ноутбуке.
PS
Схожие вопросы - обсуждались в чате тут: https://t.me/sberlogacompete/3935
Zoom link will be available at
https://t.me/sberlogabig shortly before the start.
Video records of the talks: https://www.youtube.com/c/SciBerloga - subscribe our channel !
👨🔬 Никита Бухал "Анализ feature importances - 1"
⌚️ 20 March, Monday, 20.00 (Moscow Time)
❗️Нестандартный день, время
Add to Google Calendar
Есть множество методов определения feature importances - большинство из них не идеальны. Мы начнем серию рассказов об этом вопросе.
1) Даже если фича высока по импортансу - это не гарантирует, что она реальна важна. Эксперимент - добавляем рандомные фичи смотрим их позицию, оказывается часто она достаточно высока.
2) Если фича низка по импортансу - эта НЕ означает, что она не важна. Основная проблема - избыточные фичи - "redundant" - (часто высоко-коррелированные). То есть фича сама по себе неплоха, но другие лучше, и модель выбирает их, а эта идет в конец.
Разные модели работают по разному - LGB, Лассо - обычно выбирают лишь одну фичу, а другие имеют низкий импортанс, а Ридж, Random Forest часто "расплавляют" импортанс - то есть все схожие фичи получают примерно равную долю импортанса - исходный импортанс примерно делится на число элементов группы. Если группа велика - импортанс каждого представителя мал - это создает ложное впечатление, что фича не важна. Эксперимент - добавляем дубликаты к фичам, смотрим что происходит.
В докладе будут рассказаны первые результаты подобных экспериментов. Примеры в ноутбуке.
PS
Схожие вопросы - обсуждались в чате тут: https://t.me/sberlogacompete/3935
Zoom link will be available at
https://t.me/sberlogabig shortly before the start.
Video records of the talks: https://www.youtube.com/c/SciBerloga - subscribe our channel !