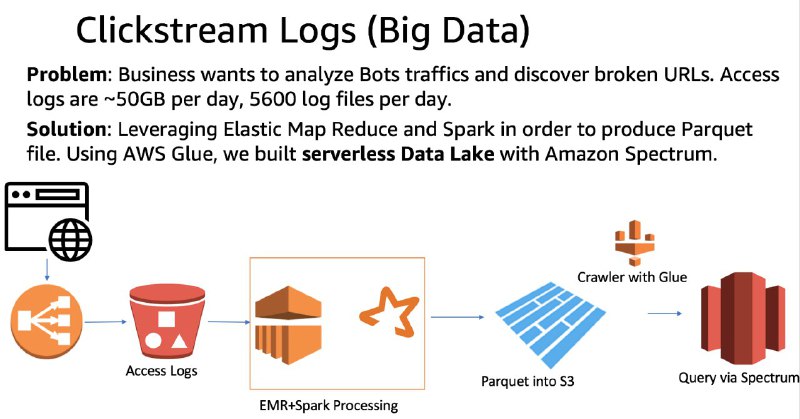
Вот мой кейс, когда traditional ELT не смог справиться с объемом, загрузка одного файла в Redshift занимает 1мин, у меня 5600 файлов в день. Поэтому использовал EMR (Hadoop) + Spark (PySpark где описал логику трансформаций). Результат сохраняется в S3 в Parquet формате. AWS Glue Crawler сканирует файлы и обновляет External Table (Hive Metastore), как результат пользователи могут писать SQL запросы через Redshift Spectrum. Примерно такое же решение можно собрать в Azure и GCP.