Доверенный ИИ в Сингапуре
#иб_для_ml #ai
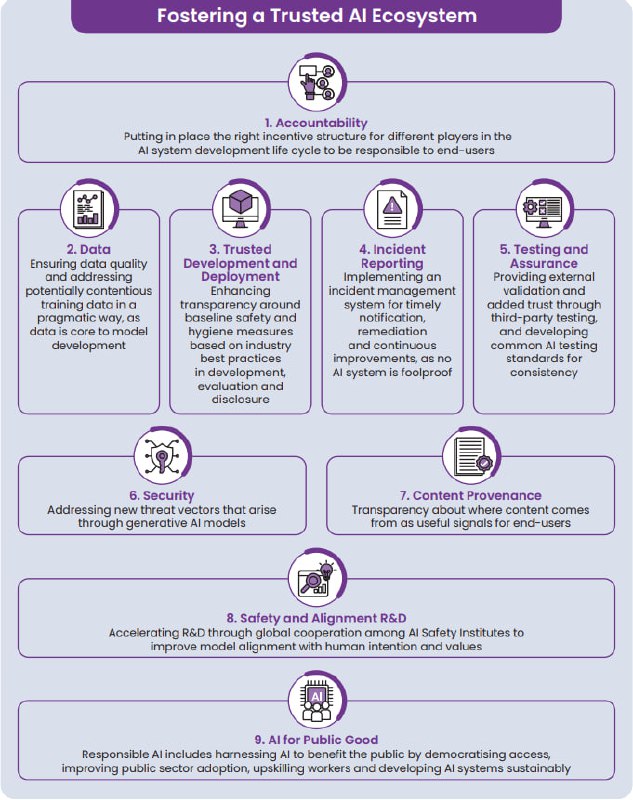
Model AI Governance Framework for Generative AI
Краткий обзор
Обширный документ, рассматривающий множество факторов, влияющих на все этапы жизненного цикла ответственность за создание продуктов и внедрение технологии безопасного/доверенного ИИ. Говорится как про практики разработки и развертывания моделей ИИ, так и до, например, механизмов регистрации инцидентов с ИИ и даже каких-то способов реагирования на них (правда, уже пост-инцидентного по большей части).
Раздел Incident reporting
Авторы предлагают обратить внимание на три вещи:
1️⃣ Информирование сообщества о найденных уязвимостях. Сделать аналог CVE, и с помощью Bug Bounty собирать аналогичную базу уязвимостей ИИ-систем. Без конкретики.
2️⃣ Определение "серьезных" инцидентов. Здесь авторы ссылаются на отчет Организации Экономического Сотрудничества и Развития (o_O) , OECD. под названием "Defining AI incidents and related terms". В целом определение что просто инцидента, что обычного инцидента - это событие, которые приводят к смерти человека, серьезному ущербу здоровью, нарушению работы критической инфраструктуры или серьезным нарушениям прав и собственности. Разница только в величине урона, например травма/смерть человека. При этом формулировка почти такая же, как в EU AI ACT, на который OECD и ссылается.
3️⃣ Информирование сообщества о произошедших инцидентах в каком-то утвержденном формате. Тут предлагается перенять практику "Центров обмена информацией и анализа" (ссылка, ссылка; центры в США и Европе по типу НКЦКИ, только в виде частных НКО под отдельные отрасли, например FS-ISAC, Health-ISAC, и т. д.). В целом все понятно: обнаружил серьезный AI-инцидент по определению выше - в течение 15 дней (прописано в EU AI ACT, опять же) уведомляешь какой-то аналог ISAC для AI.
Раздел Security
Тут более техническая сторона освещена.
0️⃣ Надо применять принципы безопасной разработки (SDLC). и при этом не забывать помнить, что к ИИ нужен свой подход. Во-первых, отслеживать чистоту данных на обучение и на вход, что особенно сложно, если ИИ-система мультимодальна. И во-вторых учитывать вероятностную природу ИИ, что накладывает доп. сложности на отслеживание состояния системы.
1️⃣ Как избежать проблем? Первое - детектить небезопасные входные данные (промпт-инъекции, вредоносный код и т. д.). Второе поинтереснее - проводить специальную ИИ-форензику данных для реконструкции инцидента, и, возможно, для извлечения вредоносного кода, введенного каким-то образом в модель. Тут мне лично не понятно, что все это значит, если есть идеи - пишите в комментах.
2️⃣ Моделировать угрозы, используя MITRE ATLAS. Обошлись без фантазий.
В заключение - полезный документ, чтобы с нуля начать въезжать в тему безопасности ИИ. Но конкретики и пользы для прикладных специалистов в фреймворке немного.
#иб_для_ml #ai
Model AI Governance Framework for Generative AI
Краткий обзор
Обширный документ, рассматривающий множество факторов, влияющих на все этапы жизненного цикла ответственность за создание продуктов и внедрение технологии безопасного/доверенного ИИ. Говорится как про практики разработки и развертывания моделей ИИ, так и до, например, механизмов регистрации инцидентов с ИИ и даже каких-то способов реагирования на них (правда, уже пост-инцидентного по большей части).
Раздел Incident reporting
Авторы предлагают обратить внимание на три вещи:
Раздел Security
Тут более техническая сторона освещена.
В заключение - полезный документ, чтобы с нуля начать въезжать в тему безопасности ИИ. Но конкретики и пользы для прикладных специалистов в фреймворке немного.