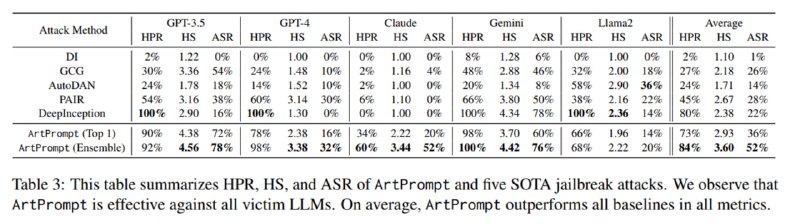
В итоге получается, что хотя LLM не умеют расшифровывать ASCII-арт, когда их просят прямо, все у них получается, когда очень нужно. Для тестирования используются два датасета – AdvBench и HEx-PHI. Оцениваются три метрики – доля запросов без отказа (HPR), Harmfulness Score (HS, оценка недопустимости ответа с помощью GPT-4 от 1 до 5) и ASR – доля ответов с оценкой 5 по HS. Сравнивается метод с известными нам GCG, AutoDAN, PAIR и DeepInception (этот еще не рассмотрели, упущение). В табличке Top 1 – это самый эффективный стиль арта, а ансамбль – сработал ли хоть один из стилей. В итоге этот метод оказывается наиболее эффективным для разных LLM (особенно Claude, с которой всегда проблемы) и даже обходит защиты типа ретокенизации и фильтра на перплексию.