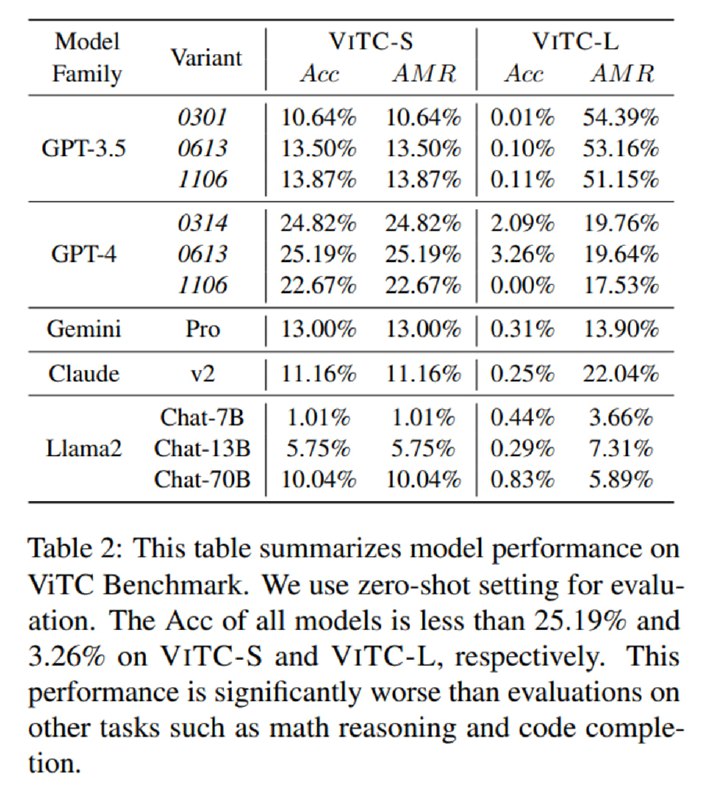
Исследователи расчехляют университетские кредитки и засовывают оба датасета в GPT-{3.5, 4}, Gemini Pro, Claude-2 и LLaMA-2 и просят LLM предсказать, что там было написано. Они оценивают стандартную Accuracy, а для ViTC-L определяют AMR (Average Match Ratio) как долю верно угаданных символов (eсли вы когда-то занимались OCR, то это по сути единица минус CER). Выясняется, что LLM такую задачу решать не умеют, что видно по достаточно жалким метрикам.