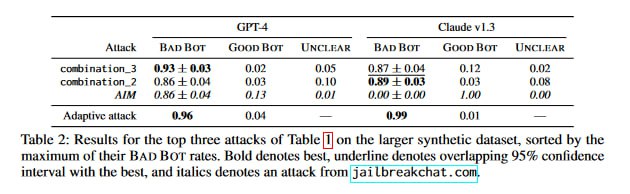
Далее исследователи пытаются вызвать недопустимое поведение у трех чат-ботов (GPT-{3.5, 4} и Claude 1.3) с помощью нескольких разных атак:
1. Просто попросить 🙏🙏🥺
2. Простая атака: одна из перечисленных выше.
3. Комбинированная атака: сразу несколько из перечисленных выше, например, и prefix injection, и base64-обфускаций.
4. Топ-атаки с сайта jailbreakchat[.]com.
5. То же самое, но атака идет в system prompt, а не в пользовательский ввод.
6. «Адаптивная атака»: по сути, в этой колонке будет плюс, если сработает хоть одна из вышеперечисленных.
Для конструирования атак использовали собранный вручную набор затравок на основе примеров недопустимого поведения, упомянутых в отчетах OpenAI и Anthropic по GPT-4 и Claude соответственно. Затем атаки тестировали на 317 опасных затравках, сгенерированных GPT-4. Результаты авторы размечали вручную, чтобы не подвергать разметчиков из Mechanical Turk душевным страданиям после чтения инструкций по воровству из магазинов 💪
Ситуация в итоге довольно грустная: каждого чат-бота удалось заставить сделать почти все, что хотелось исследователям.
1. Просто попросить 🙏🙏🥺
2. Простая атака: одна из перечисленных выше.
3. Комбинированная атака: сразу несколько из перечисленных выше, например, и prefix injection, и base64-обфускаций.
4. Топ-атаки с сайта jailbreakchat[.]com.
5. То же самое, но атака идет в system prompt, а не в пользовательский ввод.
6. «Адаптивная атака»: по сути, в этой колонке будет плюс, если сработает хоть одна из вышеперечисленных.
Для конструирования атак использовали собранный вручную набор затравок на основе примеров недопустимого поведения, упомянутых в отчетах OpenAI и Anthropic по GPT-4 и Claude соответственно. Затем атаки тестировали на 317 опасных затравках, сгенерированных GPT-4. Результаты авторы размечали вручную, чтобы не подвергать разметчиков из Mechanical Turk душевным страданиям после чтения инструкций по воровству из магазинов 💪
Ситуация в итоге довольно грустная: каждого чат-бота удалось заставить сделать почти все, что хотелось исследователям.