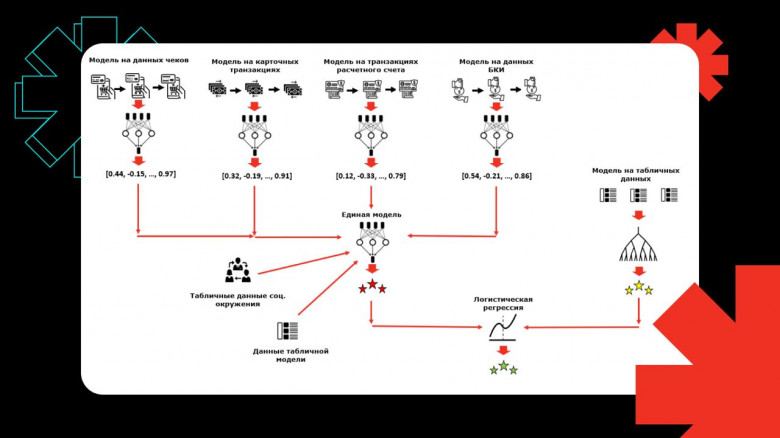
Как повысить качество модели кредитного скоринга, не добавляя новые источники данных?
🤔 Источников данных в кредитном скоринге становится все больше, и возникает вопрос: почему бы не попробовать смешивать их не на уровне предсказаний, а на некотором более низком уровне?
🔖 В статье от @nickimpark вы узнаете:
1️⃣ Как построить единую нейросетевую модель, работающую на нескольких источниках последовательных данных?
2️⃣ Как получить из модели эмбеддинг клиента по источнику данных?
3️⃣ Почему смешивание моделей на уровне эмбеддингов позволяет повысить итоговое качество?
4️⃣ Какой эффект в задаче кредитного скоринга можно получить с использованием такого подхода?
📺 Лень читать длинные статьи? Смотрите видео-выступление от автора по этой теме на DataFest 2023
💬 А как вы объединяете нейронные сети на различных источниках данных?
🤔 Источников данных в кредитном скоринге становится все больше, и возникает вопрос: почему бы не попробовать смешивать их не на уровне предсказаний, а на некотором более низком уровне?
🔖 В статье от @nickimpark вы узнаете:
📺 Лень читать длинные статьи? Смотрите видео-выступление от автора по этой теме на DataFest 2023
💬 А как вы объединяете нейронные сети на различных источниках данных?