Как научить нейронку решать задачу лучше специалиста?
Рассмотрим процесс, в котором решение принимает специалист в предметной области. Например, это может быть врач, ставящий диагноз по ЭКГ или флюорограмме, оператор колл-центра, обслуживающий клиентов, или даже дата сайентист, обучающий модели.
🤔 Как разработать модели, которые будут работать лучше этих специалистов?
👉 Пойдем по стандартному алгоритму работы DSа:
1. Начнем с глубокого интервью со специалистом, где выясним на основании каких данных и какие он принимает решения.
2. Переведем задачу в термины машинного обучения.
3. Соберем данные, необходимые для принятия решения, и целевую переменную.
4. Замеряем качество работы специалиста при помощи кросс-разметки.
Отлично, задачу поставили, данные собрали, качество замеряли.
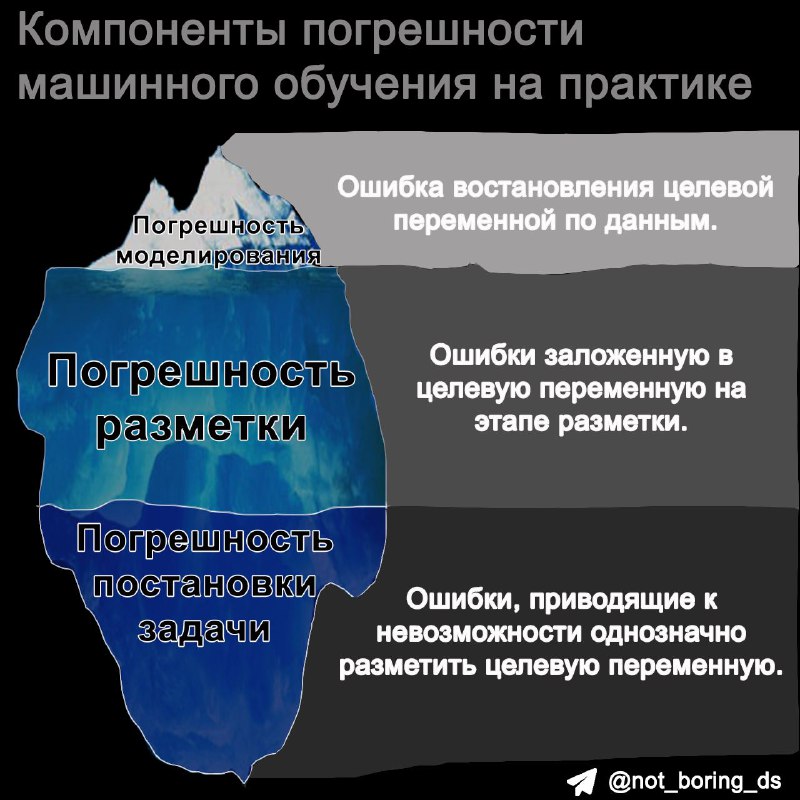
👉 Минуточку, модели машинного обучения - это не искусственный интеллект, они всего лишь учатся восстанавливать параметрическую зависимость между данными и целевой переменной и делают это с погрешностью.
😓 Получается, модель всегда будет работать хуже человека за счет наличия погрешности?
Действительно модели будут в среднем работать хуже специалиста, но есть выход:
1. Обучаться на примерах, в которых согласованы несколько специалистов.
2. Использовать в обучении примеры лучших специалистов/экспертов.
📈 Комбинация из этих подходов позволит работать лучше, чем плохой специалист и средний специалист. Лучших специалистов получится превзойти, если обучаться на разметке комитета лучших специалистов и запрещать им объединяться на практике)
🤔 Не стоит забывать про еще один тип погрешности, связанный с неточностью постановки задачи. Например, в случаях классификации на 1000+ классов авторы каталога классов могут заложить в него заведомо неразделимые для экспертов классы.
👉 В итоге, точность работы в модели в бизнес-процессе ограничивается комбинаций модельной ошибки, погрешностью в разметке и погрешностью в постановке задачи.
💬 Как бы вы поставили задачу по оптимизации работы дата сайентистов?)
Рассмотрим процесс, в котором решение принимает специалист в предметной области. Например, это может быть врач, ставящий диагноз по ЭКГ или флюорограмме, оператор колл-центра, обслуживающий клиентов, или даже дата сайентист, обучающий модели.
🤔 Как разработать модели, которые будут работать лучше этих специалистов?
👉 Пойдем по стандартному алгоритму работы DSа:
1. Начнем с глубокого интервью со специалистом, где выясним на основании каких данных и какие он принимает решения.
2. Переведем задачу в термины машинного обучения.
3. Соберем данные, необходимые для принятия решения, и целевую переменную.
4. Замеряем качество работы специалиста при помощи кросс-разметки.
Отлично, задачу поставили, данные собрали, качество замеряли.
👉 Минуточку, модели машинного обучения - это не искусственный интеллект, они всего лишь учатся восстанавливать параметрическую зависимость между данными и целевой переменной и делают это с погрешностью.
😓 Получается, модель всегда будет работать хуже человека за счет наличия погрешности?
Действительно модели будут в среднем работать хуже специалиста, но есть выход:
1. Обучаться на примерах, в которых согласованы несколько специалистов.
2. Использовать в обучении примеры лучших специалистов/экспертов.
📈 Комбинация из этих подходов позволит работать лучше, чем плохой специалист и средний специалист. Лучших специалистов получится превзойти, если обучаться на разметке комитета лучших специалистов и запрещать им объединяться на практике)
🤔 Не стоит забывать про еще один тип погрешности, связанный с неточностью постановки задачи. Например, в случаях классификации на 1000+ классов авторы каталога классов могут заложить в него заведомо неразделимые для экспертов классы.
👉 В итоге, точность работы в модели в бизнес-процессе ограничивается комбинаций модельной ошибки, погрешностью в разметке и погрешностью в постановке задачи.
💬 Как бы вы поставили задачу по оптимизации работы дата сайентистов?)