Многорукие бандиты и АБ-тесты: в поиске оптимальности
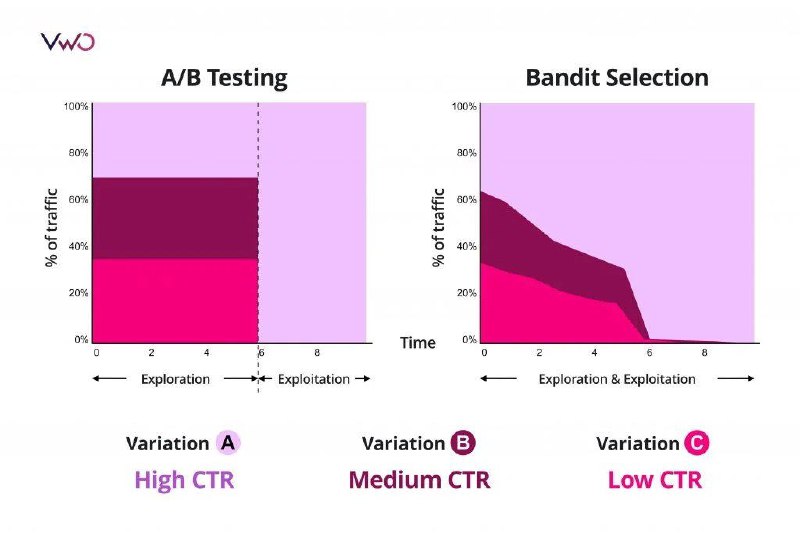
Классическое АБ-тестирование обладает критичным ограничением – мы не можем завершать эксперимент, пока не наберется необходимая выборка. Представьте, какими могут быть альтернативные издержи (условно, недополучаемая прибыль), если тестовая ветка показывает себя ощутимо лучше или хуже контрольной? А если тестовых веток 2 и больше?
В ответ на это ограничение выходят многорукие бандиты. Это интеллектуальные алгоритмы, способные динамически оптимизировать пользовательский опыт. Достигается это за счет изменения долей распределения пользователей по веткам в процессе эксперимента в пользу наиболее результативных веток. Тем самым, подобно методу обучения с подкреплением, алгоритмы стремятся максимизировать «награду».
Представьте, что вы пришли в казино поиграть в игровые автоматы. Вы, конечно же, хотите заработать. Но вы не знаете, какой автомат сейчас наиболее щедрый. АБ-тестирование в этом случае будет означать, что вы играете на каждом автомате по очереди и ждете, когда накопится статистически значимое количество игр. Это займет много времени и денег. Подход многоруких бандитов действует более умно: при значимо частых неудачах они будут переключаться на другие автоматы в поисках оптимальных, тем самым сразу стремиться играть только на наиболее перспективных автоматах.
Приходилось ли вам использовать многоруких бандитов на практике? Поделитесь своими кейсами в комментариях.
Классическое АБ-тестирование обладает критичным ограничением – мы не можем завершать эксперимент, пока не наберется необходимая выборка. Представьте, какими могут быть альтернативные издержи (условно, недополучаемая прибыль), если тестовая ветка показывает себя ощутимо лучше или хуже контрольной? А если тестовых веток 2 и больше?
В ответ на это ограничение выходят многорукие бандиты. Это интеллектуальные алгоритмы, способные динамически оптимизировать пользовательский опыт. Достигается это за счет изменения долей распределения пользователей по веткам в процессе эксперимента в пользу наиболее результативных веток. Тем самым, подобно методу обучения с подкреплением, алгоритмы стремятся максимизировать «награду».
Представьте, что вы пришли в казино поиграть в игровые автоматы. Вы, конечно же, хотите заработать. Но вы не знаете, какой автомат сейчас наиболее щедрый. АБ-тестирование в этом случае будет означать, что вы играете на каждом автомате по очереди и ждете, когда накопится статистически значимое количество игр. Это займет много времени и денег. Подход многоруких бандитов действует более умно: при значимо частых неудачах они будут переключаться на другие автоматы в поисках оптимальных, тем самым сразу стремиться играть только на наиболее перспективных автоматах.
Приходилось ли вам использовать многоруких бандитов на практике? Поделитесь своими кейсами в комментариях.