Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
arxiv.org/abs/2303.15647
Наша новая статья! Мы обозреваем методы parameter-efficient fine-tuning: от простых и популярных типа adapters или LoRa до более хитрых типа Compacter или KronA.
Продублирую сюда моё короткое описание статьи из твиттера.
PEFT methods can target several things: storage efficiency, multitask inference efficiency, and memory efficiency are among them. We are interested in the case of fine-tuning large models, so memory efficiency is a must.
I feel like everyone knows about Adapters, BitFit, and LoRa, but there are even better methods out there! In the last two years, low-rank methods took off.
Compacter and KronA use a more rank-efficient way to get large matrices. Kronecker product is the new matmul for PEFT.
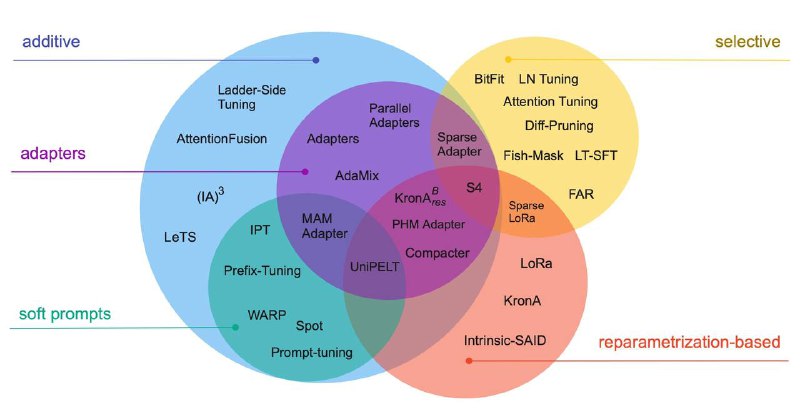
We dive into the details of 20 different PEFT methods in the paper. Still, because we understand not everyone has the time to read the full 15 pages, we highlight a one-sentence description of each method and provide a pseudocode!
arxiv.org/abs/2303.15647
Наша новая статья! Мы обозреваем методы parameter-efficient fine-tuning: от простых и популярных типа adapters или LoRa до более хитрых типа Compacter или KronA.
Продублирую сюда моё короткое описание статьи из твиттера.
PEFT methods can target several things: storage efficiency, multitask inference efficiency, and memory efficiency are among them. We are interested in the case of fine-tuning large models, so memory efficiency is a must.
I feel like everyone knows about Adapters, BitFit, and LoRa, but there are even better methods out there! In the last two years, low-rank methods took off.
Compacter and KronA use a more rank-efficient way to get large matrices. Kronecker product is the new matmul for PEFT.
We dive into the details of 20 different PEFT methods in the paper. Still, because we understand not everyone has the time to read the full 15 pages, we highlight a one-sentence description of each method and provide a pseudocode!