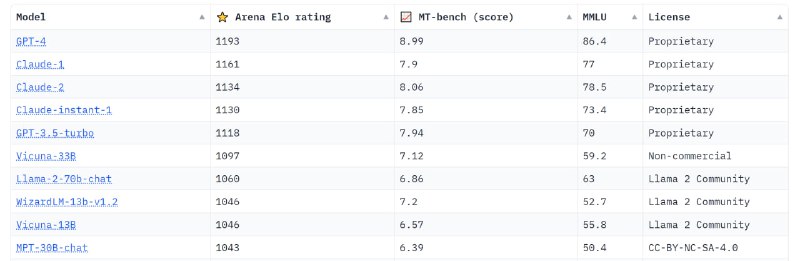
Очередной рейтинг оценки лидеров больших языковых моделей (LLM) от LMSYS - huggingface:
Arena Elo Rating - рейтинг на основе более 70 тысяч анонимных голосов Chatbot Arena (эталонная платформа для больших языковых моделей);
MT-Bench(score) - оценка с помощью судейства LLM;
MMLU - тест для измерения точности понимания языка при многозадачности текстовой модели, включает 57 задач.
За прошедшею неделю GPT-4 потеряла 13 пунктов, на третье место вышла Claude-2.
К голосованию на платформе Arena Elo Rating добавилось 20 тысяч голосов.
Arena Elo Rating - рейтинг на основе более 70 тысяч анонимных голосов Chatbot Arena (эталонная платформа для больших языковых моделей);
MT-Bench(score) - оценка с помощью судейства LLM;
MMLU - тест для измерения точности понимания языка при многозадачности текстовой модели, включает 57 задач.
За прошедшею неделю GPT-4 потеряла 13 пунктов, на третье место вышла Claude-2.
К голосованию на платформе Arena Elo Rating добавилось 20 тысяч голосов.