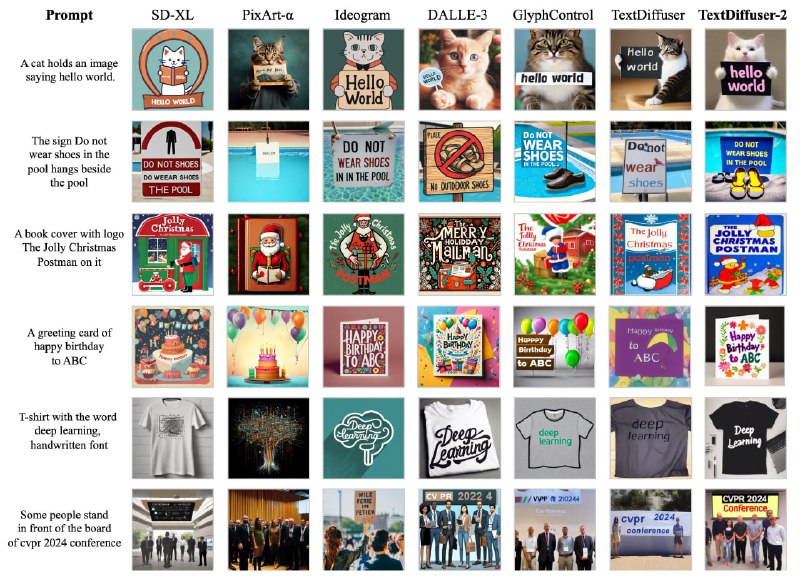
Диффузионные модели продемонстрировали свою эффективность в генерации контента, но создание визуального текста с их помощью остается сложной задачей. Хотя были предложены методы, учитывающие положение и содержание текста, они все еще ограничены из-за недостатка гибкости, предсказуемости макетов и ограниченного разнообразия стилей.
Новая нейросеть TextDiffuser-2, использует LLM для автоматического планирования макета и создания ключевых слов и применяющий языковую модель в процессе диффузии для кодирования положения и текста на строковом уровне. Этот подход позволяет генерировать более разнообразный текстовый контент. Тем не менее, у нейросети остаются ограничения при рендеринге сложных языков, поскольку она расширяет отображаемую таблицу символов за счет добавления новых токенов.
TextDiffuser-2 подойдёт для графического дизайна, рекламы и искусства, можно создавать инфографику для преподавания. Например, диаграммы с пояснительным текстом для учебных материалов.
Подписаться на Нейроскептик
Новая нейросеть TextDiffuser-2, использует LLM для автоматического планирования макета и создания ключевых слов и применяющий языковую модель в процессе диффузии для кодирования положения и текста на строковом уровне. Этот подход позволяет генерировать более разнообразный текстовый контент. Тем не менее, у нейросети остаются ограничения при рендеринге сложных языков, поскольку она расширяет отображаемую таблицу символов за счет добавления новых токенов.
TextDiffuser-2 подойдёт для графического дизайна, рекламы и искусства, можно создавать инфографику для преподавания. Например, диаграммы с пояснительным текстом для учебных материалов.
Подписаться на Нейроскептик