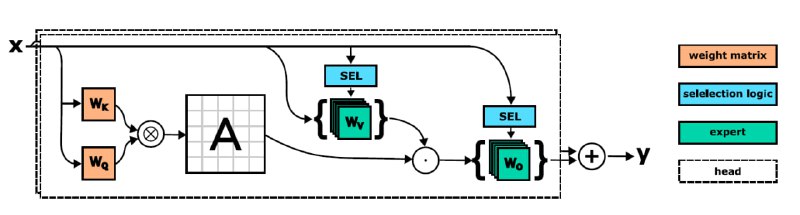
В статье SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention группа авторов представила исследование, предлагающее использование смеси экспертов для увеличения эффективности работы MultiHeadAttention в Transformer. В состав SwitchHead (на схеме) входят несколько независимых руководителей, каждый из которых имеет несколько экспертов. Каждая голова имеет единую матрицу внимания.
Авторы утверждают, что применение их подхода может ускорить процесс обучения и улучшить точность моделей.
Однако, несмотря на потенциальные преимущества, данный подход все еще требует дополнительных исследований и экспериментов. Также не ясно, как он может взаимодействовать с другими методами оптимизации, такими как остаточное обучение или регуляризация. В общем и целом, идея использования смеси экспертов может оказаться полезной для ускорения обучения Transformer, но необходимы дальнейшие исследования для определения наилучших параметров и условий применения данного подхода.
Подписаться на Нейроскептик
Авторы утверждают, что применение их подхода может ускорить процесс обучения и улучшить точность моделей.
Однако, несмотря на потенциальные преимущества, данный подход все еще требует дополнительных исследований и экспериментов. Также не ясно, как он может взаимодействовать с другими методами оптимизации, такими как остаточное обучение или регуляризация. В общем и целом, идея использования смеси экспертов может оказаться полезной для ускорения обучения Transformer, но необходимы дальнейшие исследования для определения наилучших параметров и условий применения данного подхода.
Подписаться на Нейроскептик