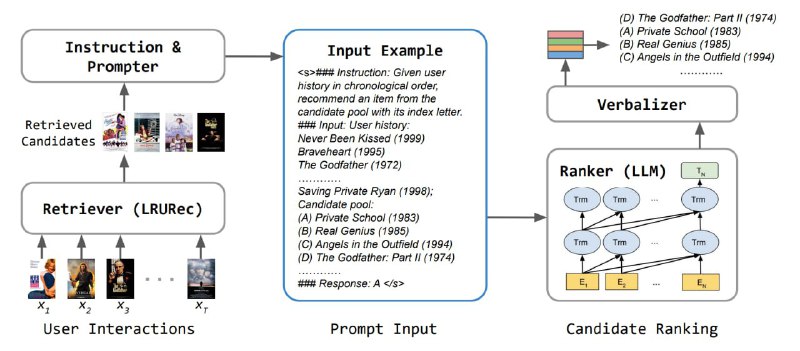
Исследователи из университета Иллинойса и NVIDIA создали двухэтапную рекомендательную структуру с использованием больших языковых моделей (LLM) - LlamaRec
Большинство существующих алгоритмов дают рекомендации без обучения, которые полагаются на предварительно полученных данных (например, рекомендации фильмов). Кроме того, вывод по LLM выполняется медленно из-за авторегрессионной генерации, что делает эти алгоритмы менее эффективными для рекомендаций онлайн.
LlamaRec использует небольшие последовательные рекомендации для поиска кандидатов на основе истории взаимодействия с пользователем. Затем история и полученные элементы передаются в LLM в текстовом виде через разработанный шаблон подсказки. Вместо генерации заголовков следующих элементов модель применяет подход, основанный на вербализаторе, который преобразует выходные логиты в распределения вероятностей по элементам-кандидатам.
Таким образом, LlamaRec может эффективно ранжировать элементы без создания длинного текста.
Подписаться на Нейроскептик
Большинство существующих алгоритмов дают рекомендации без обучения, которые полагаются на предварительно полученных данных (например, рекомендации фильмов). Кроме того, вывод по LLM выполняется медленно из-за авторегрессионной генерации, что делает эти алгоритмы менее эффективными для рекомендаций онлайн.
LlamaRec использует небольшие последовательные рекомендации для поиска кандидатов на основе истории взаимодействия с пользователем. Затем история и полученные элементы передаются в LLM в текстовом виде через разработанный шаблон подсказки. Вместо генерации заголовков следующих элементов модель применяет подход, основанный на вербализаторе, который преобразует выходные логиты в распределения вероятностей по элементам-кандидатам.
Таким образом, LlamaRec может эффективно ранжировать элементы без создания длинного текста.
Подписаться на Нейроскептик