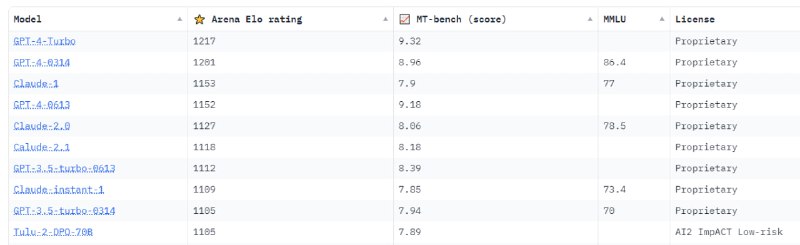
В первой десятки рейтинга оценки лидеров больших языковых моделей (LLM) от LMSYS - huggingface снова произошли изменения:
К Arena Elo Rating присоединилось ещё 30 тысяч голосов. Теперь у LLM от OpenAI появилось обозначение последнего обновления (под версия), т.е. в рейтинги уже несколько GPT-4 и GPT-3.5 Turbo. Аналогичная ситуация с LLM от Anthropic. Таким образом практически всю первую десятку заняли модели от OpenAI и Anthropic. Целесообразность такого решения весьма неоднозначна. Зачем сравнивать со старыми, не обновлёнными моделями?
Arena Elo Rating - рейтинг на основе более 130 тысяч анонимных голосов Chatbot Arena (эталонная платформа для больших языковых моделей);
MT-Bench(score) - оценка с помощью судейства LLM;
MMLU - тест для измерения точности понимания языка при многозадачности текстовой модели, включает 57 задач.
Подписаться на Нейроскептик
К Arena Elo Rating присоединилось ещё 30 тысяч голосов. Теперь у LLM от OpenAI появилось обозначение последнего обновления (под версия), т.е. в рейтинги уже несколько GPT-4 и GPT-3.5 Turbo. Аналогичная ситуация с LLM от Anthropic. Таким образом практически всю первую десятку заняли модели от OpenAI и Anthropic. Целесообразность такого решения весьма неоднозначна. Зачем сравнивать со старыми, не обновлёнными моделями?
Arena Elo Rating - рейтинг на основе более 130 тысяч анонимных голосов Chatbot Arena (эталонная платформа для больших языковых моделей);
MT-Bench(score) - оценка с помощью судейства LLM;
MMLU - тест для измерения точности понимания языка при многозадачности текстовой модели, включает 57 задач.
Подписаться на Нейроскептик