Интересная лекция о больших языковых моделях (LLM) в 2023 году от Hyung Won Chung из OpenAI
Некоторые тезисы:
Перспектива «Ещё»
Изменение точки зрения необходимо, потому что некоторые способности проявляются только на определенном уровне. Даже если что-то не работает с LLM текущего поколения, мы не должны утверждать, что это не работает в принципе. Скорее, мы должны думать, что это ЕЩЁ не работает. Когда становятся доступными более крупные модели, многие выводы меняются. Это также означает, что некоторые выводы из прошлого недействительны, и нам необходимо постоянно отучиваться от интуиции, построенной на основе таких идей.
Как на самом деле происходит масштабирование?
Если исходить из первых принципов, масштабирование Transformer сводится к эффективному выполнению матричных умножений на многих-многих машинах. Эта тема для тех, кто хочет понять, что значит обучение больших моделей.
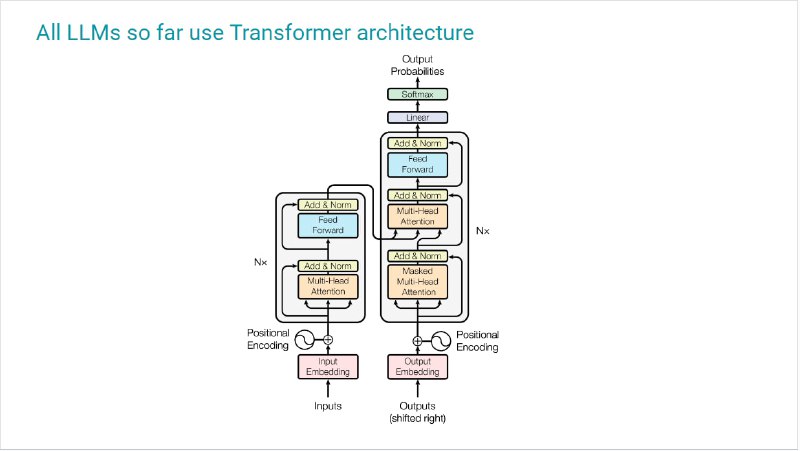
В дополнении к лекции слайды
Некоторые тезисы:
Перспектива «Ещё»
Изменение точки зрения необходимо, потому что некоторые способности проявляются только на определенном уровне. Даже если что-то не работает с LLM текущего поколения, мы не должны утверждать, что это не работает в принципе. Скорее, мы должны думать, что это ЕЩЁ не работает. Когда становятся доступными более крупные модели, многие выводы меняются. Это также означает, что некоторые выводы из прошлого недействительны, и нам необходимо постоянно отучиваться от интуиции, построенной на основе таких идей.
Как на самом деле происходит масштабирование?
Если исходить из первых принципов, масштабирование Transformer сводится к эффективному выполнению матричных умножений на многих-многих машинах. Эта тема для тех, кто хочет понять, что значит обучение больших моделей.
В дополнении к лекции слайды