Эффективное масштабирование базовых моделей в длинном контексте
Группа исследователей взяла датасет с длинными текстами, (400B токенов в сумме), и увеличили контекст LLaMA2 с 4K до 32K токенов. Важный момент: увеличить период RoPE embeddings с 10K до 50K.
Что интересно, выяснилось что предобучать модели на длинных контекстах с самого начала смысла нет. Для этого предобучили несколько LLaMA7B с нуля. Один из них всё время тренировался c 32K-len, другие модели первые 20/40/80% обучения тренировались с 4K, после чего прееключались на 32K. Разница получилась минимальной.
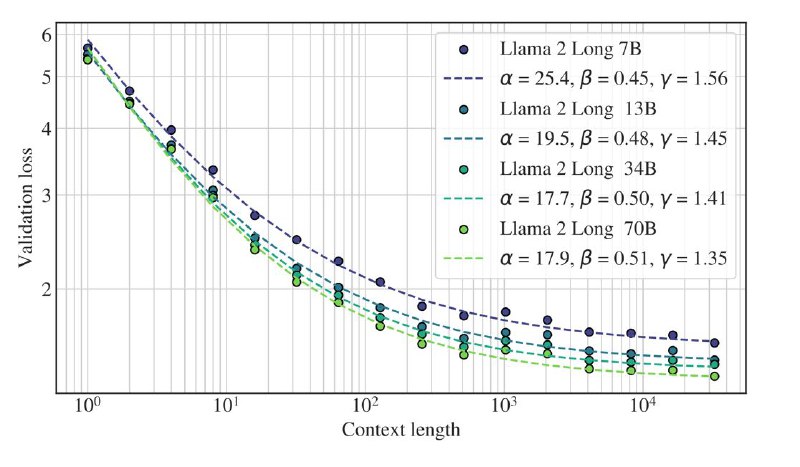
Кроме этого показали scaling law с длинной контекста (см. график выше). Это удобно тем что можно наперёд предсказывать лосс и использовать это как sanity check того что ваша тренировка идёт хорошо.
Финальные модели обходят всё что есть в опенсорсе. По метрикам в статье, включая human eval, LLaMA2 Long 70B работает так же хорошо как и chatgpt-3.5-16k.
Группа исследователей взяла датасет с длинными текстами, (400B токенов в сумме), и увеличили контекст LLaMA2 с 4K до 32K токенов. Важный момент: увеличить период RoPE embeddings с 10K до 50K.
Что интересно, выяснилось что предобучать модели на длинных контекстах с самого начала смысла нет. Для этого предобучили несколько LLaMA7B с нуля. Один из них всё время тренировался c 32K-len, другие модели первые 20/40/80% обучения тренировались с 4K, после чего прееключались на 32K. Разница получилась минимальной.
Кроме этого показали scaling law с длинной контекста (см. график выше). Это удобно тем что можно наперёд предсказывать лосс и использовать это как sanity check того что ваша тренировка идёт хорошо.
Финальные модели обходят всё что есть в опенсорсе. По метрикам в статье, включая human eval, LLaMA2 Long 70B работает так же хорошо как и chatgpt-3.5-16k.