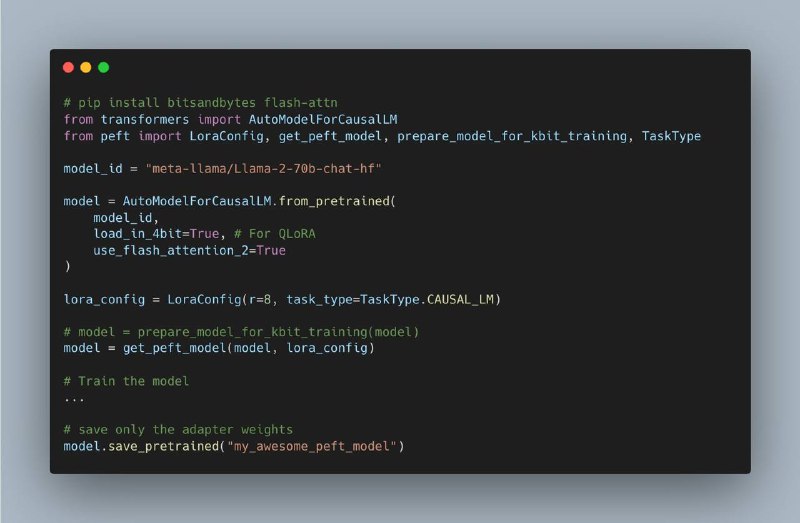
Flash Attention 2 завели прямо в трансформеры
Коротко, это мегаэффективный cuda kernel для рассчета attention, который делает ваше потребление памяти линейным вместо квадратичного, да и в принципе работает в несколько раз быстрее наивной имплементации к которой мы все привыкли.
Flash Attention 1 был в Optimum, теперь Flash 2 встроен в основную библиотеку и чтобы его использовать надо просто указать use flash attention 2 в from pretrained.
Коротко, это мегаэффективный cuda kernel для рассчета attention, который делает ваше потребление памяти линейным вместо квадратичного, да и в принципе работает в несколько раз быстрее наивной имплементации к которой мы все привыкли.
Flash Attention 1 был в Optimum, теперь Flash 2 встроен в основную библиотеку и чтобы его использовать надо просто указать use flash attention 2 в from pretrained.