Исследователи Anthropic заявили, что изучили внутренние концепции своей модели Claude Sonnet. И что это один из самых подробных отчётов по пониманию языковых моделей (LLM).
В целом, «мысли» модели представляют собой огромный список чисел, нейронов. И сам по себе он нам ни о чём не говорит. Однако, как выяснили исследователи, каждая концепция представлена через множество нейронов, и каждый нейрон участвует в представлении множества концепций. Эти концепции кодируются признаками.
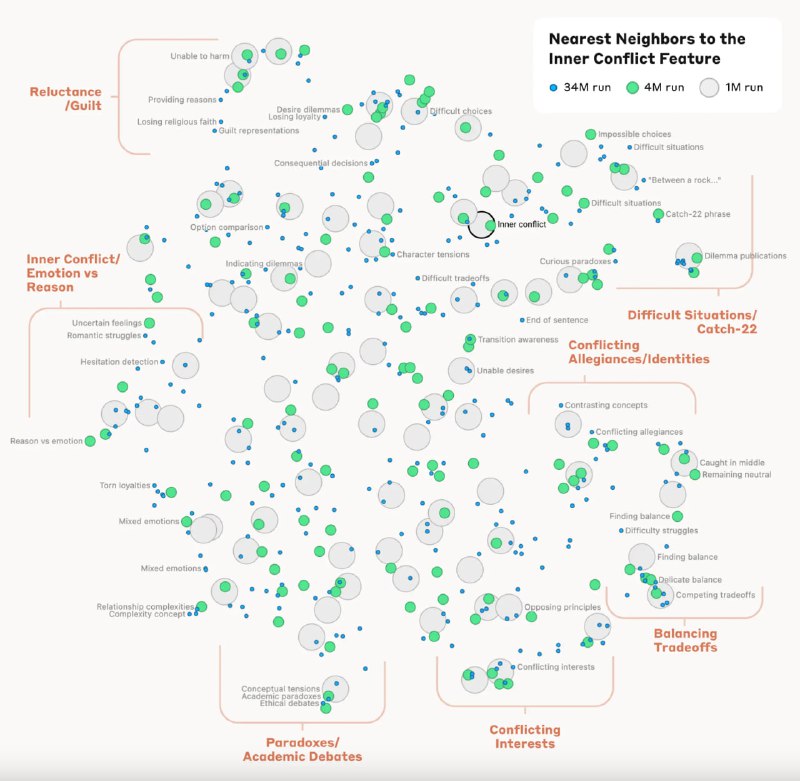
Исследователи также смогли измерить своего рода «расстояния» между признаками. Так, при исследовании признака, связанного с понятием «внутренний конфликт», были найдены признаки, связанные с расставаниями в отношениях и логическими несоответствиями. Это показывает, что внутренняя организация концепций в модели соответствует, по крайней мере отчасти, нашим человеческим представлениям о сходстве. Возможно именно поэтому Claude может делать аналогии и метафоры.