😵💫 От галлюцинаций никуда не детьсяГаллюцинациями называют ложную информацию, которую могут генерировать большие языковые модели (LLM). Для разработчиков LLM снижение количества галлюцинаций — важная задача. В новой работе исследователи
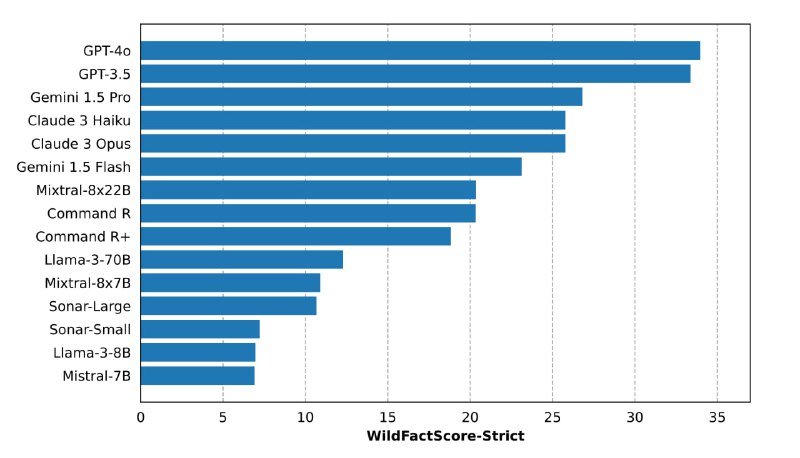
изучали, как часто галлюцинируют разные современные модели: от Mistral-7B до GPT-4o. Для оценки авторы создали метрику WILDFACTSCORE-STRICT. Она работает следующим образом: присваивает оценку 1 (то есть максимальный балл) в том случае, если все отдельные факты, содержащиеся в сгенерированном ответе, верны. Если хотя бы один факт ошибочен или модель отказалась давать ответ, присваивается оценка 0.
🪅Наилучшие результаты по этой метрике показали модели GPT-4o и GPT-3.5, но и они не были лишены галлюцинаций полностью. Интересно, что модели с функцией поиска в интернете (например, Command R и Sonar) не показали заметного преимущества по сравнению с LLM, работающими без поиска, и в некоторых случаях даже уступали им.