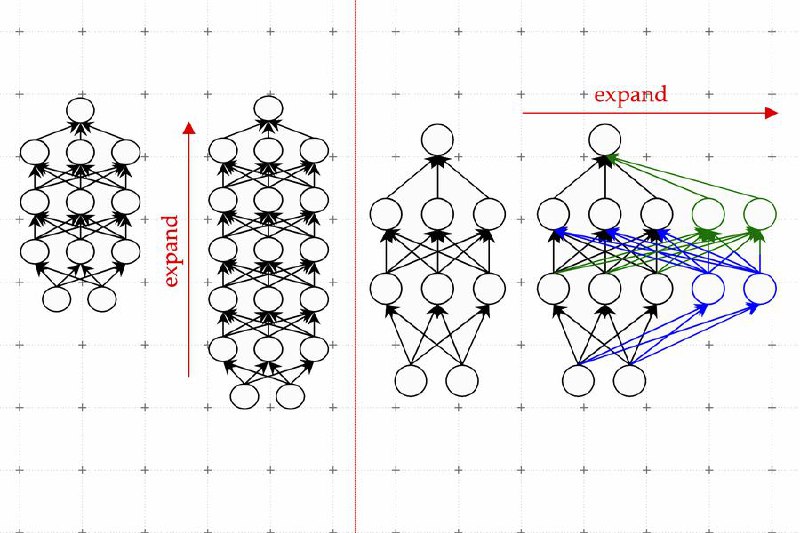
Исследователи из Массачусетского технологического института (MIT) разработали метод, который экономит около 50% вычислительных затрат, необходимых для обучения больших моделей искусственного интеллекта, таких как ChatGPT от OpenAI, с использованием предварительно обученных меньших моделей. Метод, называемый learned Linear Growth Operator (LiGO), ускоряет обучение и сокращает время, расходы и выбросы углерода, связанные с этим процессом. Быстрое и более доступное обучение может демократизировать подобные технологии и позволить меньшим исследовательским группам работать с огромными моделями, что потенциально приведет к множеству новых достижений. Исследование, проведенное совместно MIT, Университетом Техаса в Остине, лабораторией искусственного интеллекта MIT-IBM Watson и Колумбийским университетом, будет представлено на Международной конференции по представлениям обучения.
https://news.mit.edu/2023/new-technique-machine-learning-models-0322
@TG_GPT
https://news.mit.edu/2023/new-technique-machine-learning-models-0322
@TG_GPT