2 метода для semi-supervised learning
Авторы стать предлагают решения для обучения с недостатком размеченных данных.
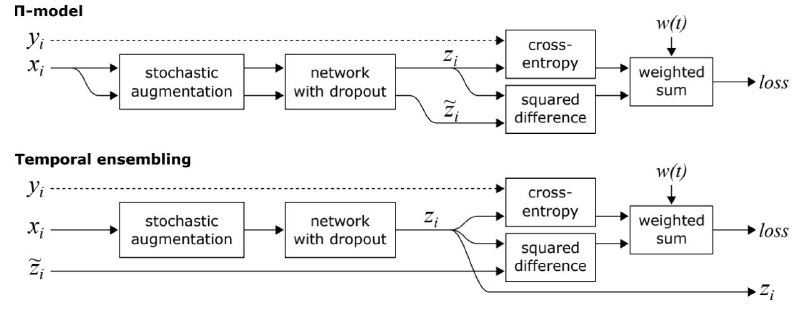
Первый метод под названием П-model.
Алгоритм: Тренируем нейронную сеть с одним из способов dropout-а, (z) тренируем вторую сеть с использованием другого dropout-а (z'). Находим loss для размеченных данных посредством cross-entropy, складываем с loss-ом для неразмеченных данных посредством squared difference, умножая на вес ramp-up function.
Второй метод улучшает результаты, и получил он название Temporal ensembling.
🐸 Во-первых он снижает количество времени для трейна за счет того, что теперь наш алгоритм будет основываться на на 2 неронках, а на 1.
🐸 Во-вторых за счет тренировки без обновления веса, результат второй сети будут более зашумленные при использовании П-model
Алгоритм:
Все то же самое, но теперь мы берем как результат z' предыдущий output модели (шаг тренировки - 1). А вернее он находится формулой αZ + (1 − α)z/(1 − α^t), t – шаг обучения (возводим в степень для нормализации startup bias, так как на первом шаге z'=0). α – ensembling momentum
Подробнее в статье
Авторы стать предлагают решения для обучения с недостатком размеченных данных.
Первый метод под названием П-model.
Алгоритм: Тренируем нейронную сеть с одним из способов dropout-а, (z) тренируем вторую сеть с использованием другого dropout-а (z'). Находим loss для размеченных данных посредством cross-entropy, складываем с loss-ом для неразмеченных данных посредством squared difference, умножая на вес ramp-up function.
Второй метод улучшает результаты, и получил он название Temporal ensembling.
Алгоритм:
Все то же самое, но теперь мы берем как результат z' предыдущий output модели (шаг тренировки - 1). А вернее он находится формулой αZ + (1 − α)z/(1 − α^t), t – шаг обучения (возводим в степень для нормализации startup bias, так как на первом шаге z'=0). α – ensembling momentum
Подробнее в статье