Пока все всполошились на moe mistral, и не задумываются о том как затюнить это мое в сумме 50b, я ожидаю новые способы сокращения обучаемых параметров уже на moe-tvoe, а пока поговорим за жессссткие вещи 😶🌫️
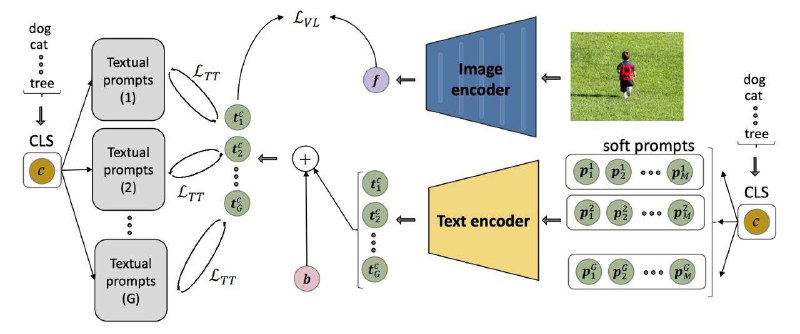
Нашла метод LASP, кторый позволяет учить CLIP в большее проявление zeroshot свойств. Получается так: берем soft prompts, но с ними есть проблема в мультимодальном dssm, потому что классы, которые уже встречались при обучении естественно будут превосходить по метрике классы, которые мы еще не встречали и сетка переобучиться. Если раньше с таким эффектом боролись с помощью KL, внедрения визуального представления в текст и других хаков, то в этот раз авторы предложили модифицировать лосс (text-to-text loss)
Общая идея в том, что можно подавать soft prompts, как мы делали бы изначально, затем после головы текстового энкодера не давать отклоняться выученным представлениям от бакета вручную написанных подсказок. При этом, мы можем разделять подсказки и формировать некоторые центроиды групп, которые будут обеспечивать zero-shot эффект и добавления виртуальных классов в обучение
🖥 Код
#PEFT
Нашла метод LASP, кторый позволяет учить CLIP в большее проявление zeroshot свойств. Получается так: берем soft prompts, но с ними есть проблема в мультимодальном dssm, потому что классы, которые уже встречались при обучении естественно будут превосходить по метрике классы, которые мы еще не встречали и сетка переобучиться. Если раньше с таким эффектом боролись с помощью KL, внедрения визуального представления в текст и других хаков, то в этот раз авторы предложили модифицировать лосс (text-to-text loss)
Общая идея в том, что можно подавать soft prompts, как мы делали бы изначально, затем после головы текстового энкодера не давать отклоняться выученным представлениям от бакета вручную написанных подсказок. При этом, мы можем разделять подсказки и формировать некоторые центроиды групп, которые будут обеспечивать zero-shot эффект и добавления виртуальных классов в обучение
#PEFT