LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking [2023] - о том, как рекомендации превратили в ЕГЭ
Итак, какой пайплайн применения LLM для ранжирования придумали товарищи из NVIDIA:
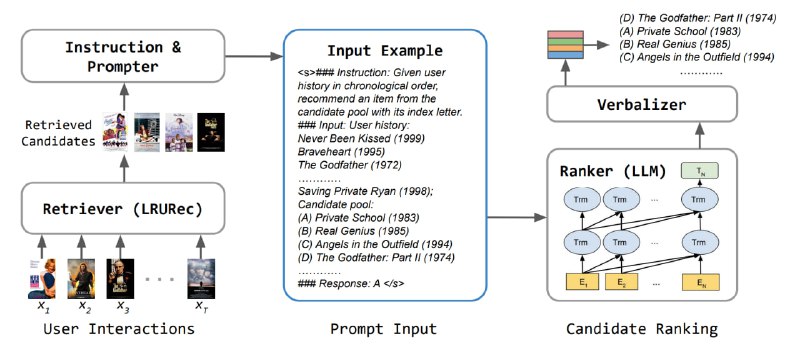
1) Кандидатогенерация без LLM - сначала рекуррентная модель под названием LRURec кушает историю пользователя и в конце выдаёт распределение на следующий документ, из которого берётся топ-20. Обучается такая модель просто с помощью next item prediction.
2) На последней стадии работает уже языковая модель в формате теста.
В качестве промпта в модель подают список названий документов, с которыми взаимодействовал пользователь. Далее модель просят предсказать наилучший следующий документ.
Мы бы хотели получать от модели распределение на следующий документ, чтобы по нему можно было отсортировать выдачу, а также иметь возможность файнтюнить LLM, максимизируя вероятность верного айтема. Чтобы этого добиться, авторы кодируют каждый возможный айтем одной буквой. Таким образом, от модели требуется написать только 1 токен в качестве ответа, на вероятности которого мы и будем смотреть.
Имеет ли смысл применять такой подход в реальной рекомендательной системе? Давайте посмотрим, чем отличается данная нейросеть от того, что мы используем у нас. Если в нашем рекомендательном трансформере вместо мешка токенов будем брать их последовательность, и склеим все эти последовательности из истории в одну, мы получим такой же формат входа, как у LlamaRec. При этом сам трансформер от LLM на порядок больше, чем тот, что мы используем у нас.
Таким образом, подобная модель стала бы неподъёмной для использования на том же размере пользовательской истории, и её пришлось бы применять на очень короткой истории. Дало ли бы это значимый ортогональный сигнал засчёт претрейна на данных из интернета? Не знаю, на мой взгляд проект выглядит слишком дорого и есть много более низковисящих фруктов.
@knowledge_accumulator
Итак, какой пайплайн применения LLM для ранжирования придумали товарищи из NVIDIA:
1) Кандидатогенерация без LLM - сначала рекуррентная модель под названием LRURec кушает историю пользователя и в конце выдаёт распределение на следующий документ, из которого берётся топ-20. Обучается такая модель просто с помощью next item prediction.
2) На последней стадии работает уже языковая модель в формате теста.
В качестве промпта в модель подают список названий документов, с которыми взаимодействовал пользователь. Далее модель просят предсказать наилучший следующий документ.
Мы бы хотели получать от модели распределение на следующий документ, чтобы по нему можно было отсортировать выдачу, а также иметь возможность файнтюнить LLM, максимизируя вероятность верного айтема. Чтобы этого добиться, авторы кодируют каждый возможный айтем одной буквой. Таким образом, от модели требуется написать только 1 токен в качестве ответа, на вероятности которого мы и будем смотреть.
Имеет ли смысл применять такой подход в реальной рекомендательной системе? Давайте посмотрим, чем отличается данная нейросеть от того, что мы используем у нас. Если в нашем рекомендательном трансформере вместо мешка токенов будем брать их последовательность, и склеим все эти последовательности из истории в одну, мы получим такой же формат входа, как у LlamaRec. При этом сам трансформер от LLM на порядок больше, чем тот, что мы используем у нас.
Таким образом, подобная модель стала бы неподъёмной для использования на том же размере пользовательской истории, и её пришлось бы применять на очень короткой истории. Дало ли бы это значимый ортогональный сигнал засчёт претрейна на данных из интернета? Не знаю, на мой взгляд проект выглядит слишком дорого и есть много более низковисящих фруктов.
@knowledge_accumulator