NoPE: лучший позишн энкодинг — это тот, которого нет
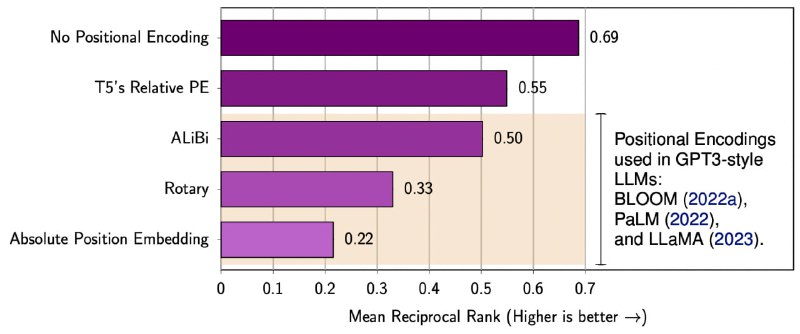
Правда ли, что позиционное кодирование критически необходимо трансформерам? Оказывается, это справедливо только для энкодеров, а вот декодеры (GPT, LLaMA и тд) могут прекрасно работать и без него!
Похоже, что каузальные маски внимания (которые не позволяют заглядывать в правый контекст) сами по себе являются отличным источником информации о позиции токенов. И более того, трансформер БЕЗ позиционного кодирования лучше обобщается на размер контекста, выходящий за длину примеров из обучения, даже по сравнению с такими мудрёными методами, как Rotary или ALiBi.
P.S. Eсли вас на собеседовании спросят зачем нужнен позишн энкодинг в GPT — можете говорить, что не особо он и нужен 💁♂️
Статья, GitHub
Правда ли, что позиционное кодирование критически необходимо трансформерам? Оказывается, это справедливо только для энкодеров, а вот декодеры (GPT, LLaMA и тд) могут прекрасно работать и без него!
Похоже, что каузальные маски внимания (которые не позволяют заглядывать в правый контекст) сами по себе являются отличным источником информации о позиции токенов. И более того, трансформер БЕЗ позиционного кодирования лучше обобщается на размер контекста, выходящий за длину примеров из обучения, даже по сравнению с такими мудрёными методами, как Rotary или ALiBi.
P.S. Eсли вас на собеседовании спросят зачем нужнен позишн энкодинг в GPT — можете говорить, что не особо он и нужен 💁♂️
Статья, GitHub