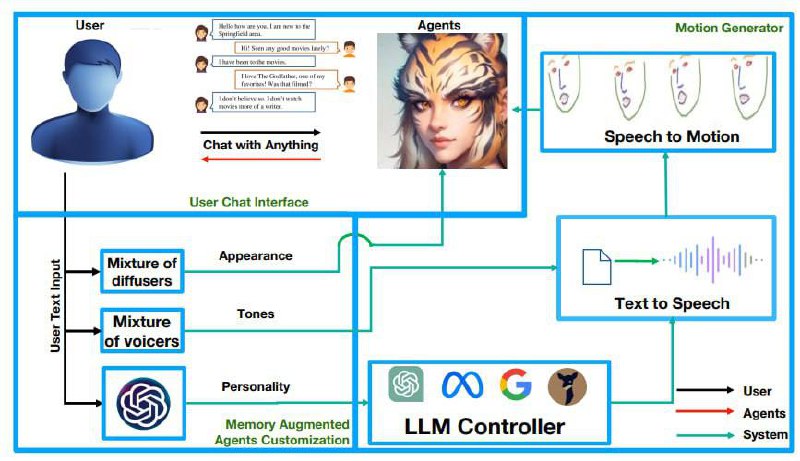
Классический пример того, как собрать готовые модели вместе и получить занятный продукт: ChatAnything
Не с кем поговорить по вечерам? аниме надоело? девушки и друзей нет? Тогда оживляем персонажа по промпту и можно болтать. По текстовому описанию или фотографии создает аватара, с которым можно общаться обычными сообщениями или голосом. Аватар будет отвечать и двигаться🤯
Что внутри?
1. LLM-based control module. Инициализирует личность описанного в тексте персонажа по ключевым словам, а также подберает диффузионого эксперта. Также лмка внутри отвечает на сообщения собеседника
2. A portrait initializer, который генерирует изображение для персонажа(смесь файтюненных диффузий(MoD) с LoRAми, здесь используются некоторые из моделей, такие как Game Iconinstitutemode, anythingv5, dreamshaper, 3D Animation Diffusion на базе stable-diffusion-v1-5). Также, используется Face-Landmark-Controlnet. Что интересно, подбирает стиль аватару автоматически
3. Микс TTS(MOV). После преобразования text-to-speech, голос синтезируется с помощью Voice-Changer. И также подбирается под заданного пользователем персонажа автоматически на этапе инициализации!!
4. A Motion generation module, который принимает речевой сигнал и формирует изображение. В данной работе используется фреймворк SadTalker для "эффекта говорящей головы" и pre-trained face keypoint detector для определения ключевых точек лица.
🖥 Код
Не с кем поговорить по вечерам? аниме надоело? девушки и друзей нет? Тогда оживляем персонажа по промпту и можно болтать. По текстовому описанию или фотографии создает аватара, с которым можно общаться обычными сообщениями или голосом. Аватар будет отвечать и двигаться
Что внутри?
1. LLM-based control module. Инициализирует личность описанного в тексте персонажа по ключевым словам, а также подберает диффузионого эксперта. Также лмка внутри отвечает на сообщения собеседника
2. A portrait initializer, который генерирует изображение для персонажа(смесь файтюненных диффузий(MoD) с LoRAми, здесь используются некоторые из моделей, такие как Game Iconinstitutemode, anythingv5, dreamshaper, 3D Animation Diffusion на базе stable-diffusion-v1-5). Также, используется Face-Landmark-Controlnet. Что интересно, подбирает стиль аватару автоматически
3. Микс TTS(MOV). После преобразования text-to-speech, голос синтезируется с помощью Voice-Changer. И также подбирается под заданного пользователем персонажа автоматически на этапе инициализации!!
4. A Motion generation module, который принимает речевой сигнал и формирует изображение. В данной работе используется фреймворк SadTalker для "эффекта говорящей головы" и pre-trained face keypoint detector для определения ключевых точек лица.