Занятная альтернатива prompt-tuning, апгрейд на бенчмарках GLUE и Super-GLUE. Понравилась работа из-за оценки схожести в эмбединговом пространстве множеств задач относительно друг друга
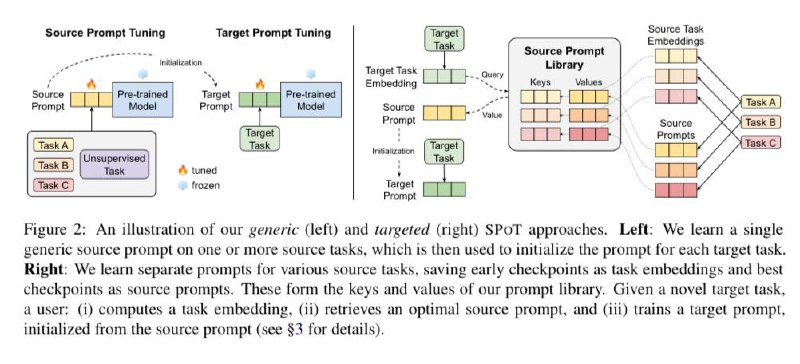
Теперь по-порядку: у prompt-tuning идея в том, что можно поставить виртуальные токены в начало и обучить только эту часть представлений.
Идея SPoT, а давайте не просто обучим, а сделаем некоторый codebook (как в vq-vae, но это условно, просто уж идея очень похожа). Как составить этот словарик? На ранних стадиях виртуальные токены берем, как значения эмбедингов задачи, а на лучшем чекпоинте (уже поучили), как source prompt (получаем словарь ключ – значение). При обучении, ищем самый близкий эмбединг задачи и настраиваем дальше его source prompt.
Смысл в том, что можно миксовать задачи и дообучать одну из другой, что судя по бенчам хорошо работает, а сам heatmap на третьем скрине
В общем-то еще один способ для мультитаска, а вот сам
🖥 код
#PEFT
Теперь по-порядку: у prompt-tuning идея в том, что можно поставить виртуальные токены в начало и обучить только эту часть представлений.
Идея SPoT, а давайте не просто обучим, а сделаем некоторый codebook (как в vq-vae, но это условно, просто уж идея очень похожа). Как составить этот словарик? На ранних стадиях виртуальные токены берем, как значения эмбедингов задачи, а на лучшем чекпоинте (уже поучили), как source prompt (получаем словарь ключ – значение). При обучении, ищем самый близкий эмбединг задачи и настраиваем дальше его source prompt.
Смысл в том, что можно миксовать задачи и дообучать одну из другой, что судя по бенчам хорошо работает, а сам heatmap на третьем скрине
В общем-то еще один способ для мультитаска, а вот сам
#PEFT