Я думала, что последние 2 недели я буду постить очень много полезной инфы, потому что сама изучаю интересное (uplift ml, мультимодальные подходы к обучению и тд), но вместо этого дошла до ловушки интенсивного обучения того, что все темы для постов стали казаться заезженными.
Сегодня вспомнила наконец-то зачем создавался этот канал, и решила запостить старинную сетку 21 года по мультимодальной детекции. Пост для тех, кто только слышал про такое или давно хотел изучить. Так что давайте вместе со мной🥰
Если начинать издалека, детекция изображенпий обычно реализовывалсь с помощью сверточных нейронных сетей (RCNN, YOLO, SSD), но потом в CV начали постепенно приходить трансформеры,и жизнь заиграла новыми красками 👽
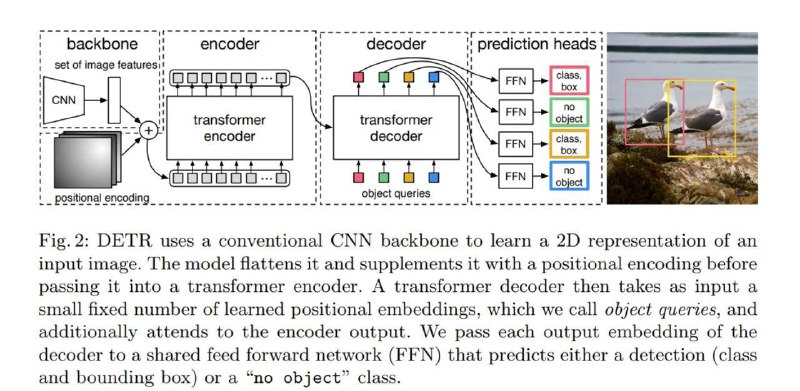
Возьмем сетку DETR. Берем backbone (как обычно в сетках детекции), только к трансформеру нас подводит positional encoding и весь цикл предсказания класса эмбеда изображения (эмбединг соответствует тому или иному заданному классу). В целом это работает, и мы получаем на выходе те же bounding box (см скрин 1)
Развитие индустрии не стояло на месте, и совмещение модальностей в задаче детекции было логическим продолжением DETR – MDETR
В MDETR, мы делаем все то же самое, только к эмбедам картинки мы конкатенируем эмбеды текста и прогоняем все через трансформер. Но что получим на выходе? Loss составной, но все части по сути – cross entropy. В первом случае высчитываем схожесть эмбединга текста с эмбедингом картинки, а в другом считаем тот самый DETR loss с принадлежностью классов к боксу.
Это кончено классно, но поговорили мы только про pretrain. Есть же и downstream таски, из которых особый интерес представляет из себя – QA по изображению. Неочевидно с первого взгляда, но авторы и здесь нашли довольно простое решение — конкатенация эмбединга, как в претрэне, с эмбедингом вопроса. И вот, вероятность ответа уже на выходе трансформера (важно посмотреть скрин 4)
Вообще, я в восхищении, особенно от идеи, что сюда прикручивают и video swin transformer, и все это великолепие способно работать еще и с видео😍
Сегодня вспомнила наконец-то зачем создавался этот канал, и решила запостить старинную сетку 21 года по мультимодальной детекции. Пост для тех, кто только слышал про такое или давно хотел изучить. Так что давайте вместе со мной
Если начинать издалека, детекция изображенпий обычно реализовывалсь с помощью сверточных нейронных сетей (RCNN, YOLO, SSD), но потом в CV начали постепенно приходить трансформеры,
Возьмем сетку DETR. Берем backbone (как обычно в сетках детекции), только к трансформеру нас подводит positional encoding и весь цикл предсказания класса эмбеда изображения (эмбединг соответствует тому или иному заданному классу). В целом это работает, и мы получаем на выходе те же bounding box (см скрин 1)
Развитие индустрии не стояло на месте, и совмещение модальностей в задаче детекции было логическим продолжением DETR – MDETR
В MDETR, мы делаем все то же самое, только к эмбедам картинки мы конкатенируем эмбеды текста и прогоняем все через трансформер. Но что получим на выходе? Loss составной, но все части по сути – cross entropy. В первом случае высчитываем схожесть эмбединга текста с эмбедингом картинки, а в другом считаем тот самый DETR loss с принадлежностью классов к боксу.
Это кончено классно, но поговорили мы только про pretrain. Есть же и downstream таски, из которых особый интерес представляет из себя – QA по изображению. Неочевидно с первого взгляда, но авторы и здесь нашли довольно простое решение — конкатенация эмбединга, как в претрэне, с эмбедингом вопроса. И вот, вероятность ответа уже на выходе трансформера (важно посмотреть скрин 4)
Вообще, я в восхищении, особенно от идеи, что сюда прикручивают и video swin transformer, и все это великолепие способно работать еще и с видео